Jekyll2026-06-22T10:49:33+00:00https://sathwick.xyz/feed.xmlhi i’m sathwick.Sathwick's blog — writing about distributed systems, infrastructure, databases, and the internals of the tools we use every day.Sathwicksathwick.p7@gmail.comI Rebuilt YouTube’s Load Balancing Algorithm in Go2026-04-20T00:00:00+00:002026-04-20T00:00:00+00:00https://sathwick.xyz/blog/prequalIf you had to guess how a system like YouTube distributes traffic across millions of backend servers, you’d probably default to a classic approach like round-robin load balancing.
But Prequal challenges that intuition. Instead of balancing traffic evenly, it focuses on balancing wait time, routing requests based on how quickly they can actually be served rather than just spreading them uniformly.
According to Google, this approach is already deployed across 20+ services, including YouTube’s serving stack (NSDI ‘24 paper).
Over the past few weeks, I’ve been reimplementing this algorithm in Go partly to understand it deeply, and partly for the bragging rights of building my own load balancer from scratch.
This post is a technical walkthrough of both the paper and codebase:
I believe the most interesting part of this repo is not just that it implements Prequal. It is that the repo preserves the engineering process of getting to a result you can trust. There are wrong runs, methodological mistakes, a regime pivot, overhead profiling, and a final bounded claim rather than a “it worked on my machine”.
Key Takeaways
Prequal is a load-balancing algorithm Google reports deploying across 20+ services, including YouTube’s serving stack (NSDI ‘24 paper).
This Go reimplementation, packaged as a Kubernetes ingress controller, cuts p99 tail latency by 8.6x vs round-robin in a paper-aligned heterogeneous regime (16 backends, 16x service-time skew, I/O-bound).
In a small CPU-bound regime (4 backends), the same implementation is roughly 25% slower than round-robin. The negative case is published alongside the positive one.
The interesting engineering story is not the algorithm itself. It is the benchmark protocol, investigation trail, and regime pivot that turned a 10x-worse false negative into a bounded, defensible claim.
What problem does Prequal solve?
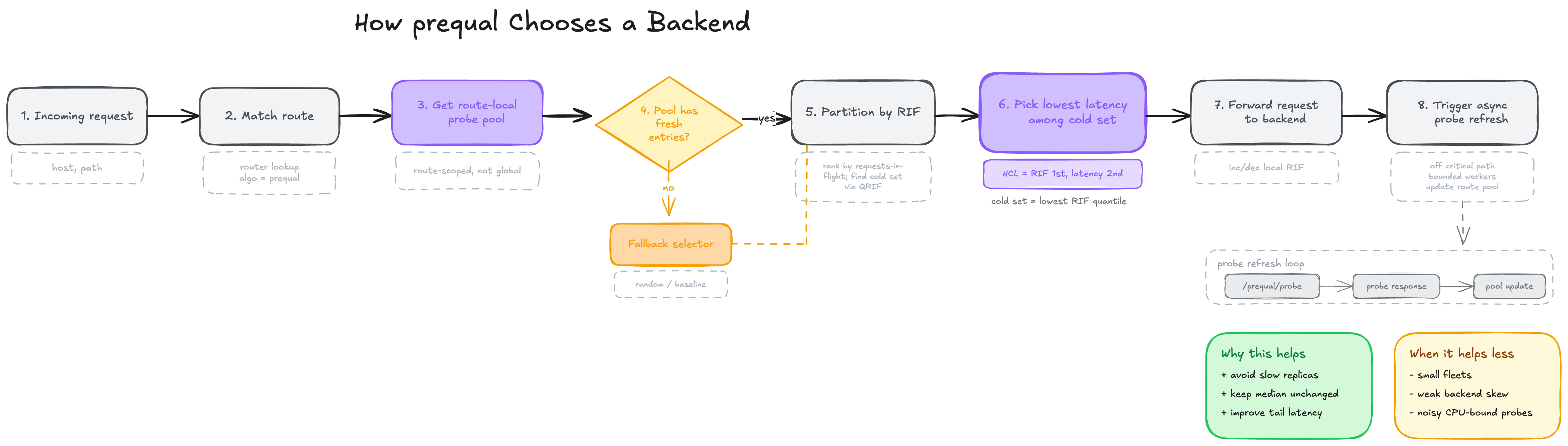
Prequal, introduced at NSDI ‘24 by Wydrowski et al., replaces CPU-based balancing with active probing of two per-backend signals: requests-in-flight (RIF) and recent latency. A hot-cold lexicographic rule picks the lowest-latency backend below an RIF quantile threshold (default 0.75), falling back to lowest-RIF when every candidate is congested.
Prequal’s central claim, from the paper is that the right signal for load balancing is not CPU utilization but expected wait time, and the paper reports that Google runs this approach across 20+ services including YouTube. The algorithm replaces smoothed load metrics with active probes of requests-in-flight and latency, then uses a hot-cold lexicographic rule on those two signals to pick a backend.
The paper starts from a real production observation inside Google: in large multi-tenant systems, balancing CPU evenly across replicas is not the same thing as minimizing latency. A backend can look “lightly loaded” according to a smoothed resource metric and still be a bad place to send the next request because it is on a noisy host, has a growing queue, or has just crossed into a regime where service time gets ugly.
That is part of what makes the paper compelling. The authors are not proposing a clever synthetic algorithm in the abstract. They are describing the load-balancing approach Google says it uses in production, especially in YouTube’s serving stack, after living with the failure modes of more conventional strategies.
Prequal’s answer is to use two signals:
RIF: requests in flight
latency: a backend-reported estimate of recent service latency
And then to sample those signals by probing backends asynchronously.
The selection rule from the paper is the part worth remembering. Prequal does not combine latency and RIF into one score by default. It uses a lexicographic rule:
Split candidates into “cold” and “hot” using an RIF quantile threshold.
If any cold candidates exist, pick the one with the lowest latency.
If every candidate is hot, pick the one with the lowest RIF.
That rule matters because it captures something simple and useful:
latency is the best tie-breaker among backends that are not yet visibly congested
once everything is congested, queue depth wins and you should pick the least loaded one
The paper calls this the hot-cold lexicographic rule, or HCL. In this repo, that is the heart of the algorithm.
If you have read about the power of two choices algorithm before, Prequal lives in the same family. Power of two picks two random backends and sends the request to whichever has fewer in-flight connections. It is cheap, surprisingly close to optimal, and widely deployed. HAProxy’s own benchmark (Power of Two Load Balancing) shows it beating round-robin on peak connection skew but still losing a few percent to a full least-connections scan. Prequal generalizes the idea: instead of two random picks checked synchronously, it keeps a small pool of asynchronous probe results and selects from that pool using both RIF and latency, not just connection count.
The other big paper idea is async probing. Synchronous probing would put an extra network hop in the critical path of every request. Prequal instead probes off the request path, stores recent probe observations in a bounded pool, and reuses them enough to be cheap without letting them go stale.
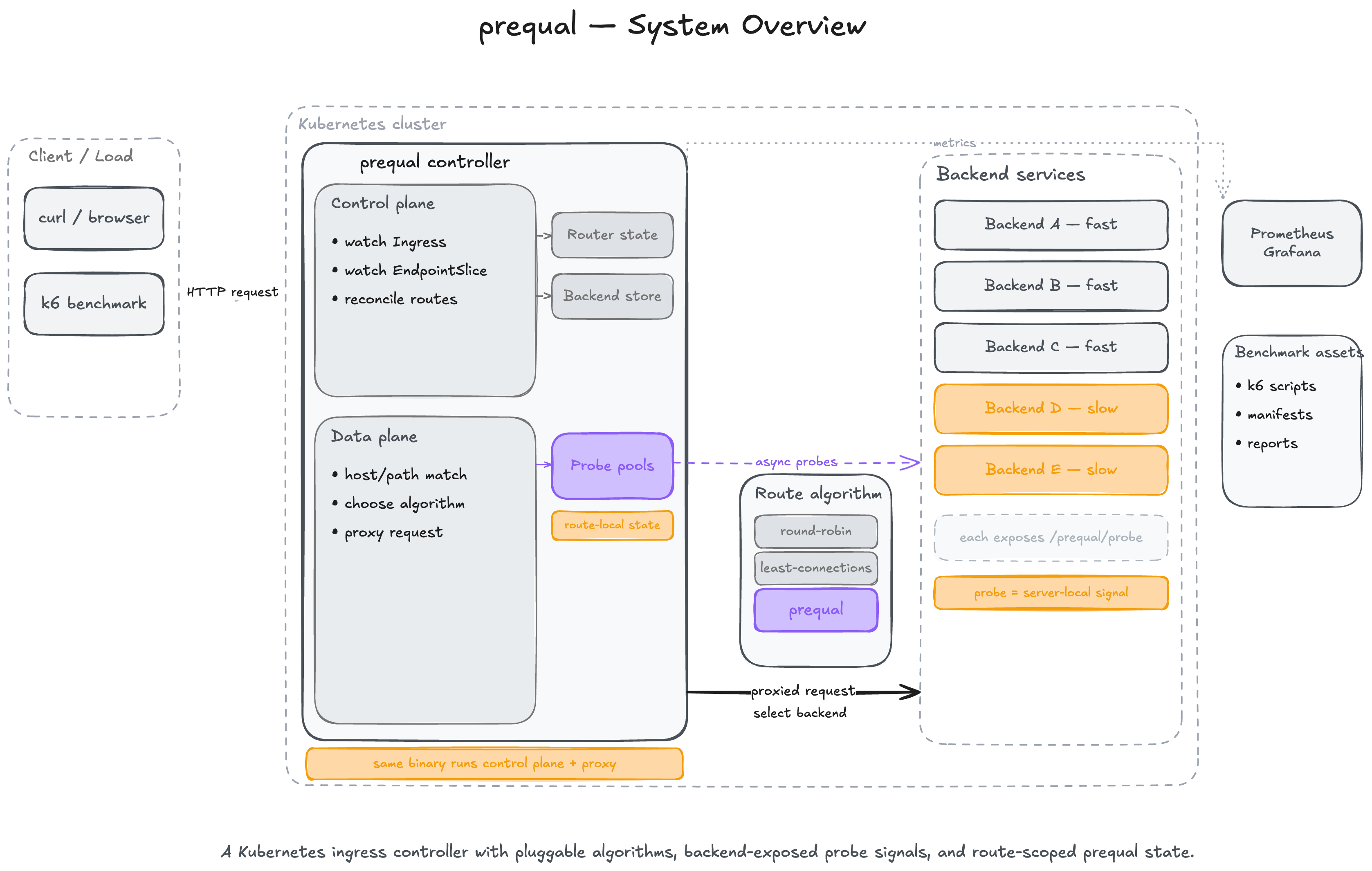
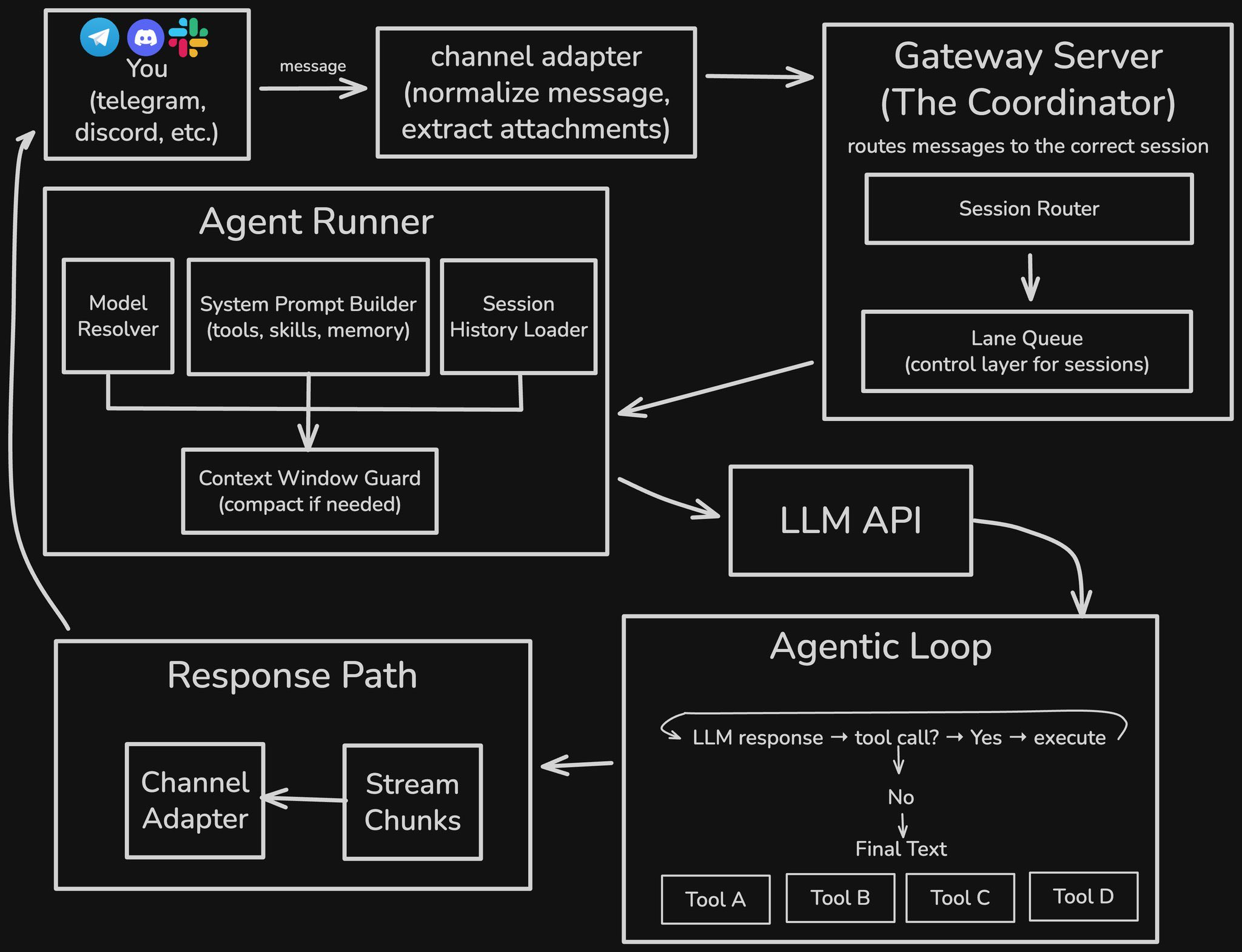
What I’ve actually built
At runtime this project is one Go binary with two jobs:
a Kubernetes controller that watches Ingress and EndpointSlice
an HTTP reverse proxy that receives requests and selects backends
Around that, the repo includes:
a Rust backend used for controlled benchmarks
benchmark manifests for uniform and heterogeneous workloads
k6 scripts for open-loop, ramp, burst, overload, multi-route, and long-duration tests
Prometheus and Grafana assets
frozen benchmark reports and investigation logs
The top-level structure is clean and maps well to the architecture:
controller/ Kubernetes reconciliation and route state
server/ Reverse proxy and request-path selection
loadbalancer/ Prequal, least-connections, round-robin, probe logic, RIF, latency, pools
backend/ Rust benchmark backend exposing /work and /prequal/probe
observability/ Prometheus metrics
tree/ Host/path trie for ingress routing
benchmark/ Manifests, k6 scripts, dashboards, reports, investigations, raw results
The entrypoint in main.go wires all of that together:
That composition is the design of the loadbalancer:
the controller owns route and endpoint discovery
the proxy owns request forwarding
the load balancer owns route-local state and selection policy
Control plane: translating Kubernetes into route state
The control plane lives in controller/. It uses shared informers to watch Ingress and EndpointSlice, then builds two in-memory structures:
a host/path router
a route-key to endpoint list store
The important point is that the controller does not directly configure nginx or write files. It builds local state for the in-process proxy.
Watching ingress and endpoints
controller.NewController registers event handlers for both resource types:
ingress add, update, delete
endpointslice add, update, delete
On an ingress event, the controller queues the ingress key for reconciliation.
On an endpoint event, it finds which ingresses depend on the service and requeues those.
That dependency mapping is stored in serviceToIngress, which is what lets endpoint churn trigger only the routes that care about it.
refreshes the endpoint store for each referenced service/port
The filtering logic accepts:
spec.ingressClassName == "prequal"
legacy kubernetes.io/ingress.class: prequal
a fallback label ingress.class=prequal
Route matching with a trie
The router in controller/router.go delegates path matching to tree/, which implements a segment trie. Each host gets a HostConfig with a list of paths plus a trie built from those paths.
tree.Match supports:
exact paths
prefix paths
longest-prefix semantics
default-host fallback when a specific host is missing
That means route resolution is:
match host
walk the trie by URL segments
prefer exact matches, otherwise keep the best prefix match
Kubernetes objects are converted once into RouteSpec, and the request path never has to understand Kubernetes types.
Endpoint storage is route-local
The controller stores endpoints in BackendIPStore, keyed by a route key derived from namespace, service, and port:
namespace/service
namespace/service:port
namespace/service:portName
That matters because the load-balancing state is also route-local. If two ingress routes point at different services, their probe history does not mix. If two routes point at the same service but different ports, their state stays separate too.
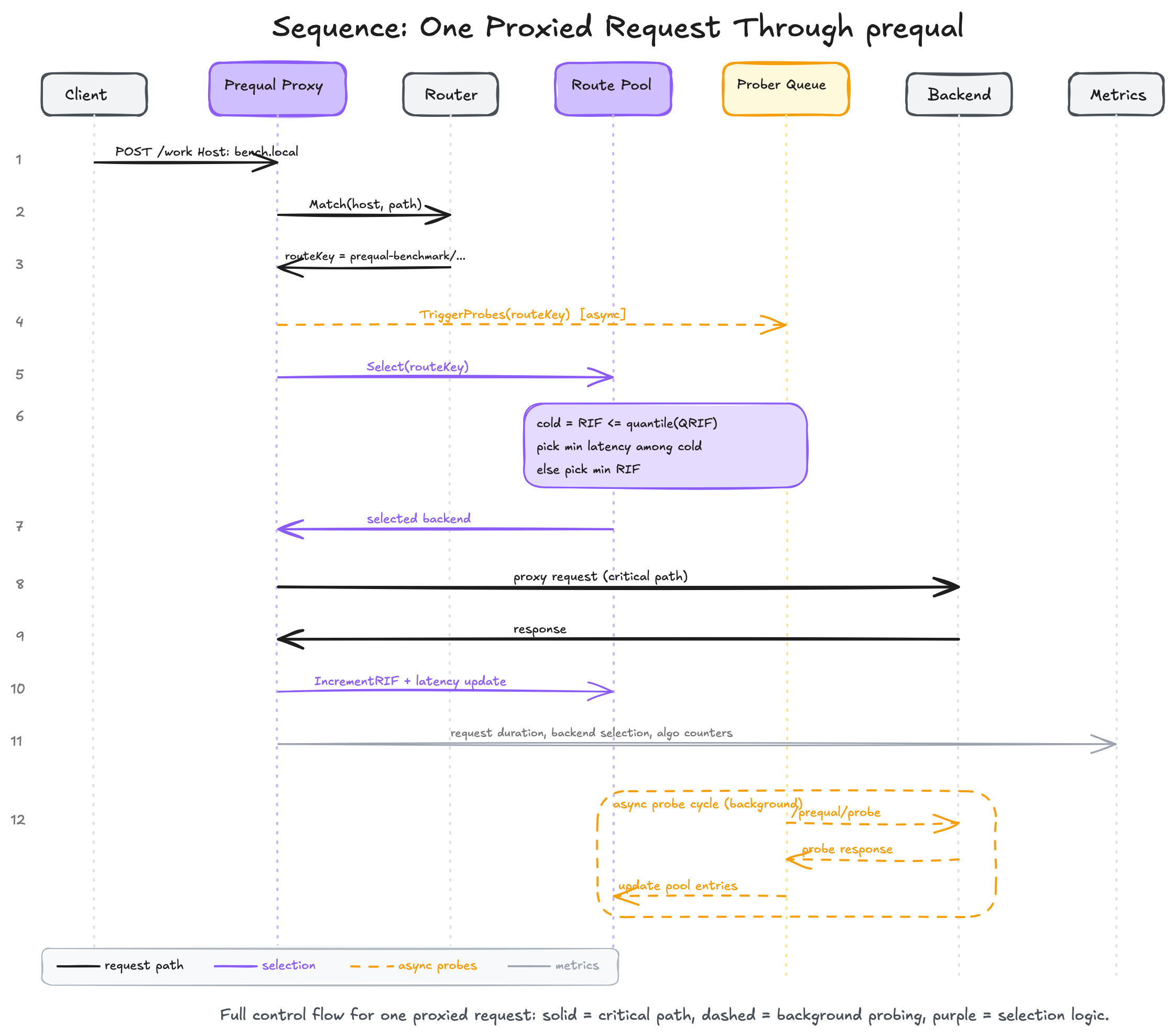
Dataplane: the reverse proxy request path
The dataplane lives in server/server.go. This is where a request enters the proxy, gets matched to a route, resolves candidate backends, triggers async probes, selects one backend, and is forwarded with httputil.ReverseProxy. For the full upstream context of how a request reaches this point (DNS, service mesh, kube-proxy, endpoints), see my earlier walkthrough on the request flow from a user to a Kubernetes pod.
The flow is:
normalize host
match route from the trie
fetch candidate backends from the endpoint store
trigger async probes for that route
pick a backend using the requested algorithm
increment RIF counters
proxy the request
record observed latency locally
That is all in one request handler, which makes the architecture easy to follow.
First, Prequal is the default. If the ingress annotation lb/algo is empty, the proxy uses Prequal.
Second, round-robin algo has been included as well.
This makes the benchmark harness clean. The same controller, proxy, transport, and backend stack can be benchmarked with different selection rules by patching one ingress annotation.
Third, the proxy increments both a global RIF tracker and the selected pool entry’s RIF view. That keeps the request path’s immediate state and the pool’s sampled state reasonably aligned.
How is Prequal implemented in Go?
The implementation is split across:
loadbalancer/prober.go
loadbalancer/pool/pool.go
loadbalancer/pool/pools.go
loadbalancer/rif.go
loadbalancer/latency.go
loadbalancer/config.go
This is the core of the repo.
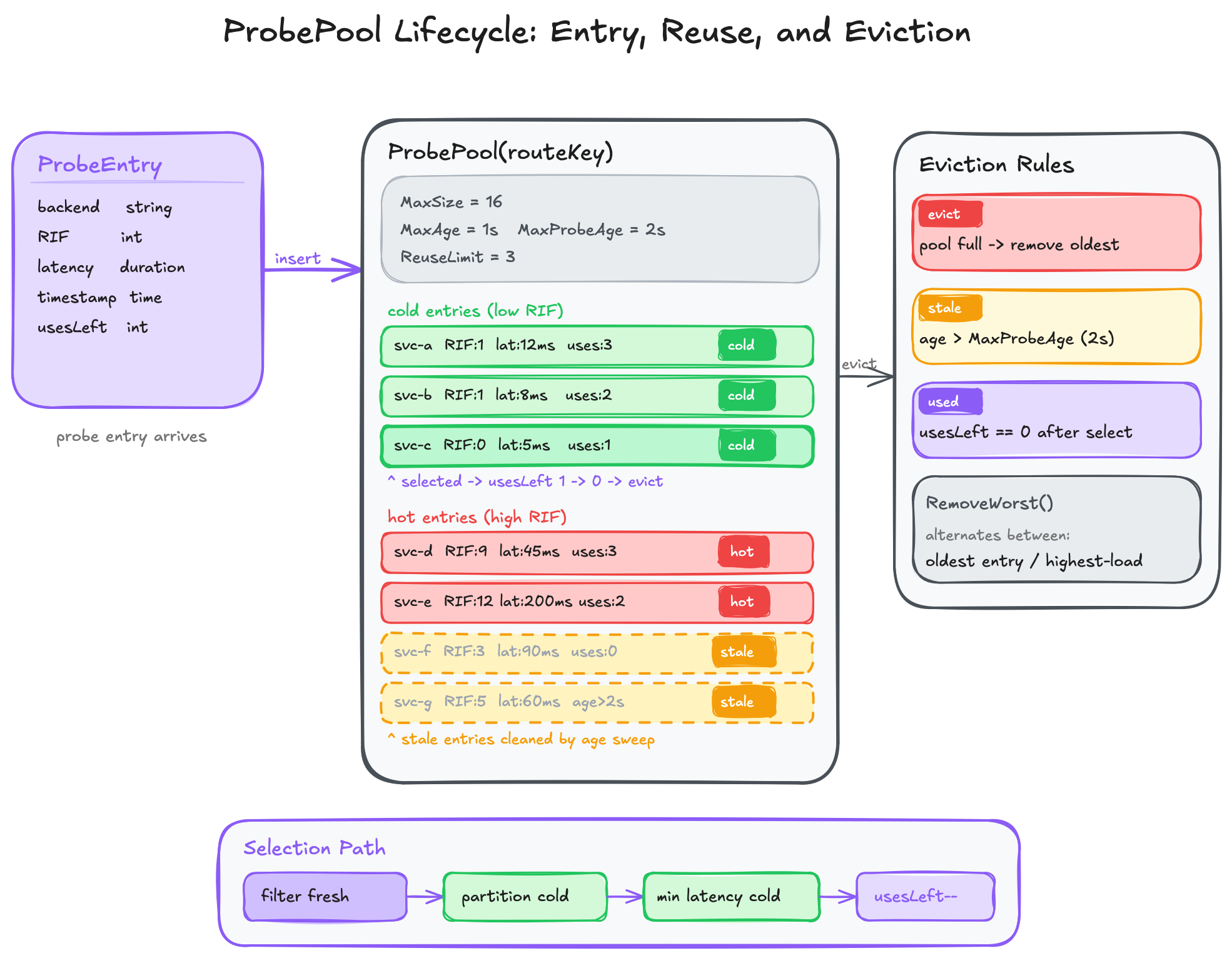
Route-local probe pools
The paper’s async probing design only works if sampled state is bounded and per-route. That is what RoutePools does: it owns one ProbePool per route key.
Each ProbeEntry holds:
backend address
endpoint pointer
RIF
latency
probe timestamp
UsesLeft
UsesLeft is the local implementation of probe reuse. A probe can be selected a limited number of times before it is evicted.
The pool is bounded by both size and age:
MaxSize
MaxAge
MaxProbeAge
That gives the lb three protection mechanisms against stale decisions:
cap how many probe samples are retained
remove entries that are too old in wall-clock terms
remove entries once they have been reused enough
HCL in code
The HCL selection rule is implemented directly in loadbalancer/pool/pool.go. This is the most important code in the project.
That is a direct implementation of the paper’s idea:
compute the RIF quantile threshold
treat RIF <= threshold as cold
among cold entries, minimize latency
if nothing is cold, minimize RIF
It is not trying to be clever, which I think is the right call here. Algorithm code gets dangerous when it becomes hard to explain. This one stays direct.
The fallback behavior is also worth noting. If the pool has fewer than two entries, the code falls back to a random backend from the full backend list. That is how the system behaves before warmup or after starvation:
The benchmark campaign explicitly tracks how often that fallback happens. In the decisive Prequal runs, it is zero, which matters because otherwise a “Prequal win” might secretly be a random-selection run.
Async probing
loadbalancer.Prober is the other half of the design. It is responsible for:
sending HTTP probes to /prequal/probe
decoding backend-reported RIF and latency
rejecting stale probe responses
feeding entries into the route-local pool
keeping pools warm in the background
The request path never blocks on probe completion. Instead, TriggerProbes(routeKey) enqueues work:
Workers consume those route keys, sample a backend for the route, call the probe endpoint, and add a ProbeEntry to the right pool.
The configuration lives in loadbalancer/config.go, and the defaults are important because they define the repo’s behavior:
pool size: 16
pool max age: 1s
reuse limit: 3
QRIF: 0.75
probes per query: 1.0
probe workers: 8
background interval: 100ms
probe timeout: 100ms
max probe age: 2s
Those values are not arbitrary, but they are also not identical to the paper’s defaults. More on this later
RIF and latency tracking
Besides backend-reported probe data, the proxy maintains its own local trackers:
RIFTracker uses sync.Map and atomic.Int64
LatencyTracker keeps a per-backend circular buffer and reports a local median
These are used for two things:
supporting least-connections
optionally seeding the probe pool when the async prober is disabled
The pool can be bootstrap-seeded from local observations if the async prober is absent, but once the prober exists, backend probes become the authoritative source.
The benchmark backend
The Rust backend in backend/src/main.rs is part of the implementation model.
It exposes three endpoints:
POST /work
GET /health
GET /prequal/probe
/work simulates the backend’s actual service time.
/prequal/probe exposes the two signals Prequal needs.
The backend’s internal state is visible in exactly the way the algorithm expects. Which makes controlled experiments possible at all.
Work mode: CPU-bound or I/O-bound
The backend has two modes:
CPU-bound SHA256 loop
I/O-bound sleep mode
That switch is controlled by IO_BOUND_MODE.
In CPU-bound mode, each request burns CPU with repeated hashing.
In I/O-bound mode, each request sleeps for iterations * IO_BOUND_BASE_US.
That one switch ends up being central to the benchmark story. On small CPU-bound fleets, Prequal loses. In the paper-aligned I/O-bound skewed regime, it wins decisively.
Probe responses are RIF-conditioned
The backend tracks current RIF with an atomic counter and stores recent latency samples in five buckets:
0
1
2..3
4..7
8+
The probe handler looks at the current RIF, chooses the matching bucket, and returns the median latency from that bucket or the nearest non-empty bucket.
This means the probe latency signal is not a raw median across all recent requests. It is conditioned on queue depth.
The Go prober then turns that into a ProbeEntry, rejects it if the timestamp is too stale, and inserts it into the right pool.
Fault injection is built in
The backend also supports probe-fault modes:
timeout
HTTP 500
malformed JSON
stale timestamp
This makes it possible to test whether the prober correctly records failures, drops bad data, and avoids poisoning the pool with stale observations.
The observability path
The controller and proxy expose Prometheus metrics for request latency, per-algorithm selections, probe success and failure counts, probe queue depth, pool occupancy, and active backend count. A debug server exposes /metrics, /routes, /healthz, /readyz, and pprof endpoints. That is enough to explain benchmark results, not just report them.
This repo instruments the controller and proxy heavily enough that you can explain a benchmark result rather than just report it.
That instrumentation is what makes the benchmark investigation credible. The repo can answer questions like:
Did Prequal actually avoid the slow replicas?
Was the pool starving?
Were requests falling back to random?
Was the controller CPU-bound?
Was mutex contention the problem?
The observability here is how the benchmark results got debugged, not dashboard decoration.
Benchmarking
A controlled protocol (interleaved algorithm order, controller rollout-restart per run, warmup period, full metadata capture) turned an early 10x-worse false negative into a reproducible 8.6x p99 improvement. The methodology fix alone, with zero algorithm code changed, produced a 56x p99 reduction in the heterogeneous run.
The benchmark harness in benchmark/ is extensive enough that it deserves to be treated as part of the software, not just support files.
There are several traffic models:
steady_state.js
open_loop.js
rate_ramp.js
burst.js
overload.js
long_duration.js
multi_route.js
And there are matching manifests for:
uniform workloads
heterogeneous workloads
multi-route workloads
route-scale
long-duration
fault injection
The comparisons are made by holding everything constant except the algorithm annotation on the ingress.
That gives a fair comparison:
same controller binary
same route matching
same transport
same backend images
same cluster
same load script
same observability stack
Only the backend selection rule changes.
The controlled protocol
The methodology fix alone, with zero algorithm code changed, produced a 56x p99 reduction in the E-B heterogeneous run. The seven competing hypotheses are walked in here
An early heterogeneous run made Prequal look dramatically worse than the baselines, but it turned out the main problem was protocol:
algorithms were run sequentially instead of interleaved
controller state leaked across runs
probe pools were not reset cleanly between repetitions
This is a better choice than closed-loop when the point is to expose queueing behavior. Closed-loop traffic self-throttles when latency rises. Open-loop keeps pushing at the target rate and makes tail failures visible.
The ramp benchmark does the complementary thing: it increases arrival rate in stages until the system crosses its comfortable regime.
Together, those two tests are enough to answer the important question: does Prequal help under skew and near saturation, which is exactly where the paper says it should?
How much faster is Prequal than round-robin?
On a 16-backend cluster with 16x service-time skew (I/O-bound, open-loop), this Go Prequal implementation cut p99 tail latency by 8.6x versus round-robin and 8.5x versus least-connections. On a 4-backend CPU-bound cluster, the same implementation was roughly 25% slower than round-robin on throughput. Prequal is a tail-latency tool, not a small-fleet tool.
Across five-run interleaved campaigns on a 16-backend cluster with 16x service-time skew, this Prequal implementation cut p99 tail latency by 8.6x against round-robin and 8.5x against least-connections on an open-loop workload, and by 6.8x against round-robin on a rate ramp. On a small 4-backend CPU-bound workload, the same implementation was roughly 25% slower than round-robin on throughput. The repo’s final claim is deliberately bounded, and I think it is the right one.
Small CPU-bound fleet: Prequal loses
In the small-fleet CPU-bound regime, this implementation does not win.
The report’s C1 numbers are:
algorithm
throughput rps
p99 ms
prequal
4162
29.86
round-robin
5366
20.22
least-connections
4965
23.48
That is roughly a 25% throughput deficit versus round-robin.
I profiled it and the overhead investigation concludes that:
there is no hot path dominating controller CPU
mutex contention is negligible
heap use is tiny
the measurable cost is mostly diffuse probe/network competition in a regime where the algorithm does not have enough diversity or skew to pay for itself
Paper-aligned skewed I/O-bound regime: Prequal wins hard
The story changes once the benchmark is moved closer to the paper’s assumptions:
16 backends instead of 4
14 fast, 2 slow
16x service-time skew
I/O-bound backend mode
open-loop and ramp traffic
In the E-B heterogeneous open-loop campaign, the median p99 numbers are:
algorithm
p99 ms
p99.9 ms
prequal
94.20
272.38
round-robin
807.32
887.90
least-connections
802.84
1006.78
That is an 8.6x p99 improvement versus the best baseline.
In the E-B ramp campaign:
algorithm
p99 ms
p99.9 ms
prequal
123.39
824.08
round-robin
831.58
1250.41
least-connections
867.93
1596.51
That is still a 6.8x p99 improvement.
The selection-rate data explains why. Prequal pushes traffic almost entirely to the fast backends and drives the two slow replicas down to nearly zero selections per second. Round-robin, by definition, keeps giving the slow pair their fair share. Least-connections improves the p95, but still reacts too slowly to avoid queueing at the slow replicas, so the tail remains pinned near their service time.
This mechanism lines up with the result
The win is in the tail, not the center
One subtle but important point from the data is that p50 is basically the same across algorithms in the winning regime. The advantage is almost entirely in p99 and p99.9.
That is exactly what you would expect if the algorithm is avoiding pathological queueing rather than making the median request faster.
It is also why Prequal is interesting. If your median is already fine, the only remaining reason to build a more sophisticated load balancer is to keep a minority of requests from getting stuck behind bad backend choices.
How faithful is this Go implementation to the Prequal paper?
This Go implementation defaults to Q_RIF = 0.75 versus the paper’s 0.84, probes-per-query = 1.0 versus the paper’s 3 (testbed) and 5 (YouTube production), and hardcodes probe reuse at 3 rather than deriving it from pool size and fleet size. The frozen benchmark report documents every divergence explicitly.
This repo is faithful to the paper’s central ideas, but it is not a line-by-line reproduction. The frozen report documents the differences clearly, and they matter.
The most important divergences are:
QRIF default is 0.75, not the paper’s ~0.84
The paper’s baseline uses Q_RIF = 2^(-0.25) ≈ 0.84.
This repo defaults to 0.75.
That is within the paper’s recommended band and probably a minor difference, but it is still a difference.
Probes per query is 1.0, not 3 or 5
The paper uses 3 probes per query in testbed experiments and mentions 5 in YouTube production.
This repo defaults to 1.0.
That choice was motivated by keeping probe overhead reasonable on a small local cluster, but it is a substantial departure.
Probe reuse is a fixed constant
The paper derives reuse behavior from a formula involving pool size, fleet size, probe rate, and removal rate.
This repo hardcodes PoolReuseLimit = 3.
That is a reasonable engineering choice for a local implementation, but it means the repo is approximating one part of the paper’s mechanics rather than reproducing it exactly.
Probe removal is maintenance-driven
The paper frames removal as a per-query process.
This repo performs cleanup and “remove worst” behavior on a maintenance tick plus reuse depletion.
That keeps work off the request hot path, which is sensible for Go code in a proxy, but it is another behavioral difference.
Backend probing is not yet sampling without replacement
The report points out a latent issue: ProbeRandom picks one backend at a time with rand.Intn, so if probes-per-query were raised above 1, the implementation would not yet match the paper’s “sample without replacement” requirement.
Final thoughts
Writing this was a lot of fun—and watching Claude run tests and benchmarks made it even better. There were a couple of ideas I wanted to explore further but didn’t get to, mainly because I was short on time and wanted to move on to the next project.
One idea was to build a sidecar container or probe that uses eBPF to attach to the main backend container, collect both latency and RIF, and expose that data through a path that the ingress controller could use to make smarter routing decisions. Another was to design a centralized probe pool that multiple ingress controller pods could read from, or to implement a gossip protocol between controller pods to share this information in a decentralized way.
But eventually, it was time to move on. As always, the next project always tends to pull more than the last.
HAProxy Technologies. Power of Two Load Balancing — context for why Prequal’s quantile-over-pool design is a more sophisticated variant of the same “sample a subset, don’t score every backend” idea.
Full source code: github.com/sathwick-p/prequal — the controller, reverse proxy, Rust benchmark backend, k6 scripts, Prometheus/Grafana assets, and frozen benchmark reports all live here.
]]>Sathwicksathwick.p7@gmail.comReverse-Engineering Claude Code: A Deep Dive into Anthropic’s AI-Powered CLI2026-03-31T00:00:00+00:002026-03-31T00:00:00+00:00https://sathwick.xyz/blog/claude-codeTable of Contents
Claude Code is Anthropic’s official CLI tool — an interactive, AI-powered development assistant that lives in your terminal. It lets developers have natural-language conversations with Claude to edit files, run shell commands, search codebases, manage Git workflows, create pull requests, debug issues, and much more.
But underneath the conversational interface lies a remarkably sophisticated piece of software engineering: a custom React-based terminal renderer, a multi-layered permission system, an elastic tool discovery mechanism, a self-healing query loop with automatic context compression, and an extensibility framework spanning skills, plugins, and the Model Context Protocol (MCP).
This article is a deep technical analysis of the Claude Code source code — approximately 330+ utility files, 45+ tool implementations, 100+ slash commands, 146 UI components, and a custom terminal rendering framework — all written in TypeScript with React, running on Bun.
Let’s take it apart, piece by piece.
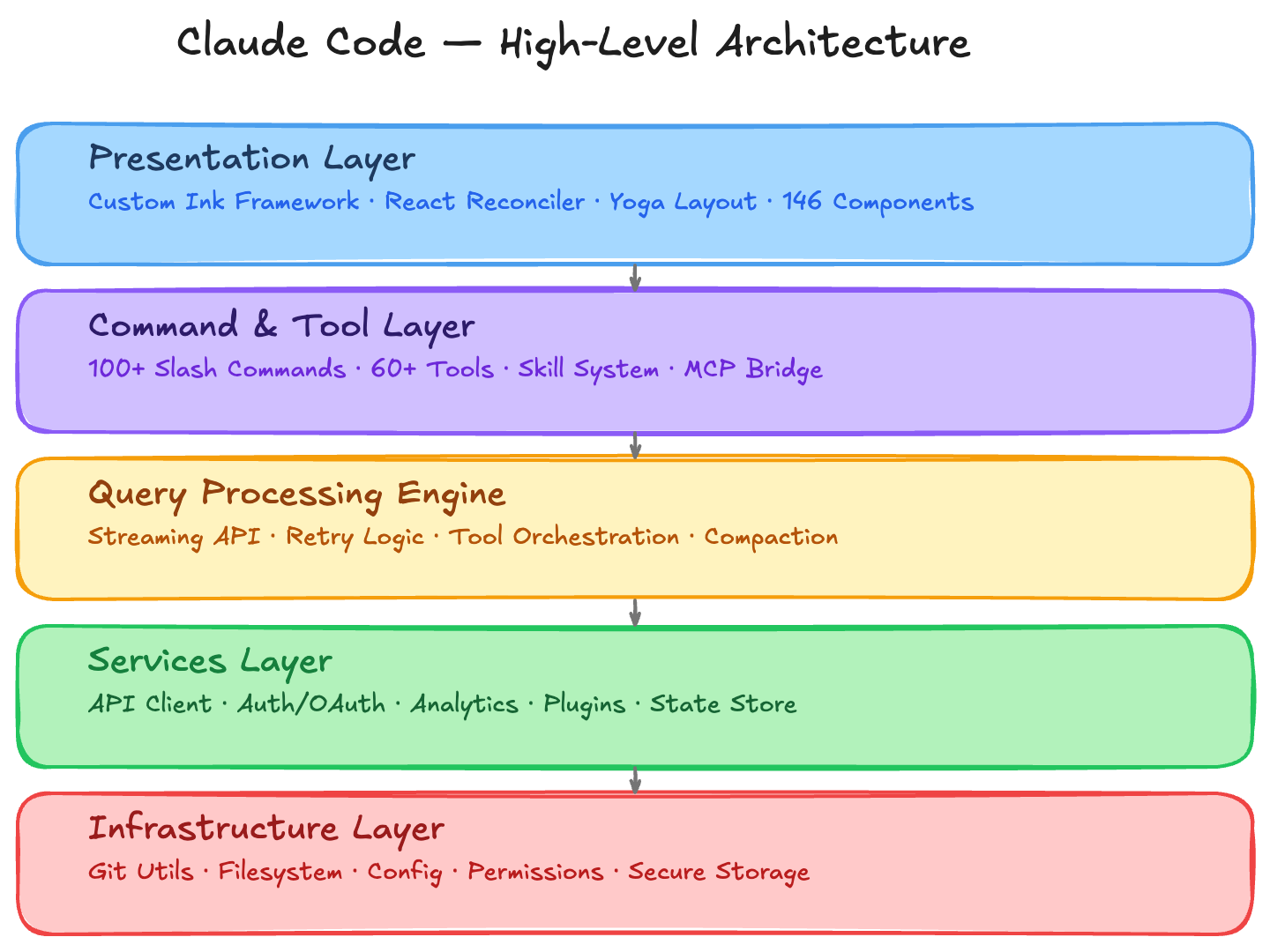
2. High-Level Architecture
Claude Code follows a layered architecture where each layer has clear responsibilities:
Claude Code’s startup is aggressively optimized. The goal: minimize time-to-first-render so the developer is never left staring at a blank terminal.
3.1 Parallelized Prefetching
Before any module imports happen, three critical operations fire in parallel:
// main.tsx — lines 1-20, before any other importsprofileCheckpoint('main_tsx_entry')startMdmRawRead()// macOS MDM policy read (subprocess)startKeychainPrefetch()// OAuth + API key keychain reads (2 subprocesses)
This exploits a clever insight: TypeScript module evaluation takes ~135ms anyway (sequential by nature). By spawning subprocesses immediately, macOS keychain reads (~65ms total) run entirely in parallel with import resolution, becoming effectively free.
3.2 Initialization Sequence
The init() function (memoized to prevent re-entrancy) orchestrates 16 setup stages:
Config validation — Parse and validate all JSON config files
Safe environment variables — Apply non-sensitive env vars before trust dialog
CA certificates — Load extra root CAs before first TLS handshake
LSP manager — Language Server Protocol cleanup handlers
Team cleanup — Multi-agent swarm cleanup on shutdown
3.3 Fast Paths
Before full initialization, fast paths handle quick-exit commands:
--version — Print version and exit (no init, no React)
--dump-system-prompt — Output the system prompt and exit
mcp serve — Start MCP server mode (different init path)
3.4 Startup Profiling
A sampled profiler (startupProfiler.ts) measures every phase:
100% of internal builds get sampled
0.5% of external users are sampled
CLAUDE_CODE_PROFILE_STARTUP=1 forces full profiling with memory snapshots
The decision is made once at module load time — non-sampled users pay zero profiling overhead.
3.5 Entrypoint Resolution
The system identifies its execution context early and sets CLAUDE_CODE_ENTRYPOINT:
Value
Context
cli
Interactive terminal session
sdk-cli
Non-interactive (print mode, piped)
mcp
Running as an MCP server
local-agent
Spawned as a subagent
claude-code-github-action
GitHub Actions CI
This gates feature loading — for example, REPL components only load in interactive mode.
4. The Query Engine: Brains of the Operation
The query engine is the core loop that manages conversations with Claude. It’s split across two files: QueryEngine.ts (session-level orchestration) and query.ts (per-turn state machine).
4.1 QueryEngine: The Session Coordinator
The QueryEngine class is a singleton per conversation. It persists state across turns and coordinates:
System context building (git status, CLAUDE.md files, date)
Usage tracking — Tracks currentMessageUsage and lastStopReason
Tool dispatch — Routes tool calls to the orchestrator
Tool execution uses a sophisticated concurrency model:
partitionToolCalls(blocks[]):
├─ Batch 1: Read-only tools A, B, C → runConcurrently(max=10)
├─ Batch 2: Write tool D → runSerially()
├─ Batch 3: Read-only tools E, F → runConcurrently(max=10)
└─ ...
Each tool’s isConcurrencySafe() method determines if it can run in parallel. Read-only tools (glob, grep, file reads) run concurrently; write tools (edits, bash with side effects) run serially with context propagation between batches.
A streaming tool executor can even begin executing tools while the model is still streaming, reducing latency by overlapping computation and I/O.
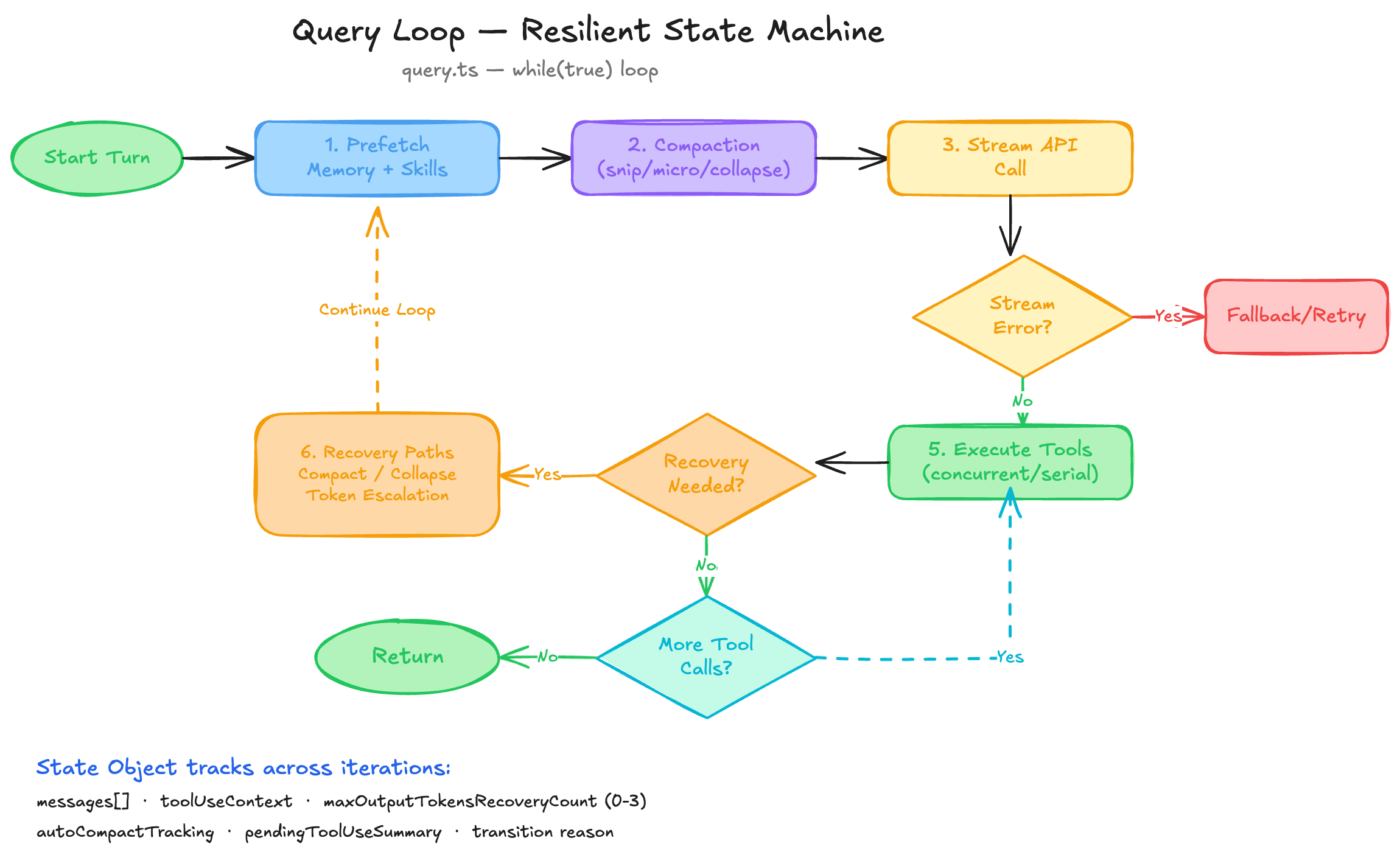
4.4 Token Budget Continuation
When the model’s output budget is approaching exhaustion but the task isn’t complete, the engine:
Injects an invisible meta-message: “Resume directly — no apology, no recap”
Continues the loop with a token_budget_continuation transition
Tracks cumulative tokens without interrupting the user
Detects diminishing returns to avoid infinite loops
Maximum 3 consecutive output-token recovery attempts before surfacing the stop reason.
5. The Tool System: 60+ Tools Behind a Single Interface
Every tool in Claude Code conforms to a single generic interface:
interfaceTool<Input,Output,Progress>{name:stringdescription():string// Dynamic, permission-context-awareprompt():string// System prompt additionsinputSchema:ZodSchema<Input>// Zod → JSON Schema for APIcall(input:Input,context:ToolContext):Promise<ToolResult<Output>>checkPermissions(input:Input):PermissionResultvalidateInput(input:Input):ValidationResultisConcurrencySafe(input:Input):boolean// 4-tier renderingrenderToolUseMessage(input:Input):ReactNoderenderToolUseProgressMessage(input:Input,progress:Progress):ReactNoderenderToolResultMessage(output:Output):ReactNoderenderToolUseErrorMessage(error:Error):ReactNodemapToolResultToToolResultBlockParam(output:Output,id:string):ToolResultBlockParam}
5.1 The Tool Registry
Tools are loaded through a feature-gated registry:
assembleToolPool(permissionContext,mcpTools):1.getTools(permissionContext)// Filter built-ins by deny rules2.filterToolsByDenyRules()// Remove blanket-denied MCP tools3.uniqBy(name)// Deduplicate (built-ins win)4.sort(name)// Alphabetical for prompt cache stability
Sorting by name is a subtle but important optimization: it keeps the tool list in the same order across requests, maximizing prompt cache hit rates on the API side.
5.2 Deferred Tool Discovery
Not all 60+ tools are sent to the model in every request. Tools marked shouldDefer: true are hidden until the model explicitly searches for them via ToolSearchTool:
Model: "I need to create a task..."
→ Calls ToolSearchTool("task create")
→ Returns TaskCreateTool schema
→ Model calls TaskCreateTool in the same turn
~18 tools are deferred: LSP, TaskCreate, MCPTool, SkillTool, EnterPlanMode, etc. This keeps the base prompt under 200K tokens while allowing elastic discovery.
5.3 Key Tool Implementations
BashTool — Command Execution with Guardrails
The most frequently used tool runs shell commands with extensive safety:
30K character result limit — Large outputs persist to disk with a preview
Sandbox awareness — Detects containerized vs. native execution
Multiline mode — rg -U --multiline-dotall for cross-line patterns
VCS exclusion — Auto-skips .git, .svn, .hg
Three output modes — Content, file paths only, or match counts
LSPTool — Language Intelligence
9 operations powered by Language Server Protocol:
goToDefinition, findReferences, hover
documentSymbol, workspaceSymbol
goToImplementation, prepareCallHierarchy
incomingCalls, outgoingCalls
Only loaded when an LSP server is connected. Deferred by default.
WebSearchTool — Native Web Search
Server-side web search (beta feature):
Max 8 searches per invocation
Domain filtering — allowed_domains and blocked_domains parameters
Streaming results — Interleaves text and citation blocks
5.4 Tool Result Budgeting
Every tool has a maxResultSizeChars limit:
Tool
Limit
BashTool
30,000 chars
GrepTool
20,000 chars
FileReadTool
Infinity (never persists)
When output exceeds the limit, it’s saved to ~/.claude/tool-results/{uuid}/output.txt and the model receives a preview with a file reference. FileReadTool is exempt because persisting its output would create a circular dependency (Read → persist → model reads persisted file → …).
5.5 Lazy Schemas
Tool input schemas use a lazySchema() factory that defers Zod instantiation:
This prevents circular import cycles (Tool.ts ← tools/ ← Tool.ts) and enables mid-session schema changes when feature flags flip.
6. The Permission System: Safety at Every Layer
Claude Code’s permission system is one of its most sophisticated subsystems — a multi-layered defense that balances safety with developer productivity.
typePermissionResult=|{behavior:'allow',updatedInput?:Input}// Hooks can modify input|{behavior:'ask',message:string}// Prompt user|{behavior:'deny',message:string}// Block with explanation
The updatedInput field is powerful: pre-execution hooks can transparently modify tool parameters (e.g., adding safety flags to shell commands).
7. Terminal UI: React, but for Your Terminal
Perhaps the most impressive subsystem in Claude Code is its custom terminal rendering framework — a complete reimplementation of React rendering for terminal environments, rivaling web browsers in sophistication.
Only subtrees with dirty ancestors are re-laid out, providing incremental performance.
7.5 Double Buffering and Blitting
The renderer uses classic graphics techniques:
Double buffering:
privatefrontFrame:Frame// Currently displayedprivatebackFrame:Frame// Being rendered into// After render: swap pointers[this.frontFrame,this.backFrame]=[this.backFrame,this.frontFrame]
Blitting (copy unchanged regions):
blit(src:Screen,x,y,width,height)// If a region hasn't changed, copy from previous frame// instead of re-rendering — the "GPU blit" technique for terminals
When a selection overlay is applied, it “contaminates” the frame, disabling blit for the next render to prevent visual artifacts.
7.6 Screen Buffer: The 2D Cell Model
The screen is a 2D array of cells:
typeCell={char:string// Interned via CharPoolwidth:CellWidth// 1 (normal), 2 (wide/CJK/emoji), -1 (tail of wide char)styleId:number// Interned via StylePoolhyperlink?:number// Interned via HyperlinkPool}
Three interning pools minimize memory and enable O(1) comparisons:
CharPool — Deduplicates character strings, returns integer IDs
HyperlinkPool — Deduplicates OSC 8 URLs (reset every 5 minutes to bound growth)
The style pool’s transition() method is especially clever:
// Pre-computed: "how to go from style A to style B"transition(fromId:number,toId:number):string{constkey=fromId*0x100000+toIdreturntransitionCache.get(key)// O(1) vs. diffing AnsiCode arrays}
7.7 Scroll Optimization
ScrollBox uses hardware scroll regions when available:
CSI top;bottom r → Set scroll region
CSI n S → Scroll up n lines (DECSTBM)
This is dramatically faster than rewriting 50+ rows of content. For smooth animation, scroll deltas accumulate and drain at terminal-specific rates:
// Native terminals: proportional drain (~3/4 per frame)conststep=Math.max(MIN,(abs*3)>>2)// xterm.js: adaptive (instant for ≤5, smaller steps for fast scrolls)conststep=abs<=5?abs:abs<12?2:3
7.8 Event System
Events follow DOM semantics with capture and bubble phases:
functioncollectListeners(target,event):DispatchListener[]{// Walk from target to root// Capture handlers: root-first// Bubble handlers: target-first}
Event priority mirrors web browsers:
Priority
Events
Discrete (sync)
keydown, keyup, click, focus, blur, paste
Continuous (batched)
resize, scroll, mousemove
7.9 Text Selection
Full text selection with word and line modes:
Character mode — Drag selects character by character
Word mode — Double-click selects word; subsequent drag extends by word boundaries
Line mode — Triple-click selects line; drag extends by lines
Scroll tracking — Text that scrolls off-screen is accumulated for correct copy
Soft-wrap handling — Wrapped lines are joined into logical lines when copying
7.10 Keyboard Input Parsing
Terminal keyboard input is notoriously ambiguous. The parser handles multiple protocols:
Kitty Keyboard Protocol — CSI u with codepoint + modifiers
Checks system health: API connectivity, auth status, model availability, MCP server connections, permission configuration.
9. Skills, Plugins, and MCP: The Extensibility Trifecta
9.1 Skills
Skills are markdown-based prompt templates with frontmatter metadata:
---name:my-skilldescription:What this skill doeswhenToUse:When Claude should invoke itallowedTools:[Bash,Read,Edit]model:claude-sonnet-4-6userInvocable:true---Skill prompt content here...
Discovery sources (5):
.claude/skills/ — Project-level skills
~/.claude/skills/ — User-level skills
Bundled skills — Compiled into the binary
Plugin skills — From installed plugins
MCP skill builders — Auto-generated from MCP servers with Prompt capability
Forked execution: Skills with context: 'fork' run in isolated subagents with their own token budgets, preventing large skills from consuming session context.
Bundled skills support lazy extraction of reference files to disk with per-process nonce-based path protection (defends against symlink/TOCTOU attacks).
MCP tools are normalized and prefixed: mcp__server__toolname. They receive the same permission checks, deny rules, and analytics as built-in tools.
10. Context Management: Fighting the Token Limit
With conversations that can last hours and generate hundreds of tool calls, managing the context window is critical. Claude Code uses a multi-strategy approach.
10.1 Auto-Compaction
When token count exceeds context_window - 13,000:
Strip images/documents from older messages (replace with [image] markers)
Group messages by API round (assistant + tool results)
Call the compaction model to generate a summary
Replace old messages with a CompactBoundaryMessage
Re-inject up to 5 files + skills post-compaction (50K token budget for files, 25K for skills)
A circuit breaker prevents thrashing: max 3 consecutive compaction failures before giving up.
10.2 Microcompaction
Lighter-weight compression for tool results:
Time-based — Clear tool results older than a TTL
Size-based — Truncate when accumulated tool result tokens exceed threshold
Cache-aware — A “cached” variant preserves prompt cache integrity via CacheEditsBlock
10.3 Snip Compaction
A history truncation strategy (feature-gated):
Remove old messages beyond a snip boundary
Preserve the assistant’s “protected tail” for context continuity
Track tokens freed for accurate token budget calculations
Full history preserved in REPL for UI scrollback (non-destructive)
10.4 Context Collapse
Staged collapses are committed lazily — only when the API returns a 413 (prompt too long):
API 413 → Collapse drain (commit staged collapses)
→ If insufficient → Reactive compact (full summarization)
→ If still insufficient → Surface error to user
10.5 System Context
Two tiers of context are injected into every request:
System context (memoized per session):
Git status (branch, recent commits, file status — truncated at 2000 chars)
Cache breaker (optional debug injection)
User context (memoized per session):
CLAUDE.md file contents (auto-discovered from project + parent directories)
Current date (ISO format)
11. State Management: Immutable Store for a Mutable World
Speculation is a latency optimization: while the user is still typing, the model begins generating a response speculatively. File writes go to an overlay filesystem (writtenPathsRef), and on completion, the overlay is either committed (if the user’s actual input matches the speculation boundary) or discarded. isPipelined indicates whether a suggestion was already generated and is queued for display.
11.3 Centralized Side Effects
All state mutations that affect external systems flow through onChangeAppState():
Permission mode changes → Notify CCR bridge
Model changes → Persist to user settings
Settings mutations → Clear auth caches
View changes → Persist UI state
One choke point, no scattered side effects.
12. Session Persistence and History
12.1 Transcript Recording
The engine records transcripts with ordering guarantees:
Assistant messages — Fire-and-forget (lazy JSON stringify with 100ms drain)
Pre-compact flush — Writes preserved segment before compaction boundary
Even if the process is killed mid-request, the conversation is resumable from the last recorded transcript.
12.2 History System
Two-level history with deduplication:
In-memory:pendingEntries[] — Queue before flush to disk
On-disk:~/.claude/history.jsonl — Append-only log
typeLogEntry={display:string// Formatted prompt for Ctrl+R pickerproject:string// Current project rootsessionId:SessionIdtimestamp:numberpastedContents?:Record<number,StoredPastedContent>}
Small pastes (<1KB) inlined; large pastes stored with hash references
12.3 Cost State Persistence
Session costs survive process restarts:
getStoredSessionCosts()// Retrieve if session ID matchessaveCurrentSessionCosts()// Persist before session switchrestoreCostStateForSession()// Restore on resume (validates session ID)
13. Multi-Agent Architecture: Subagents, Swarms, and Worktrees
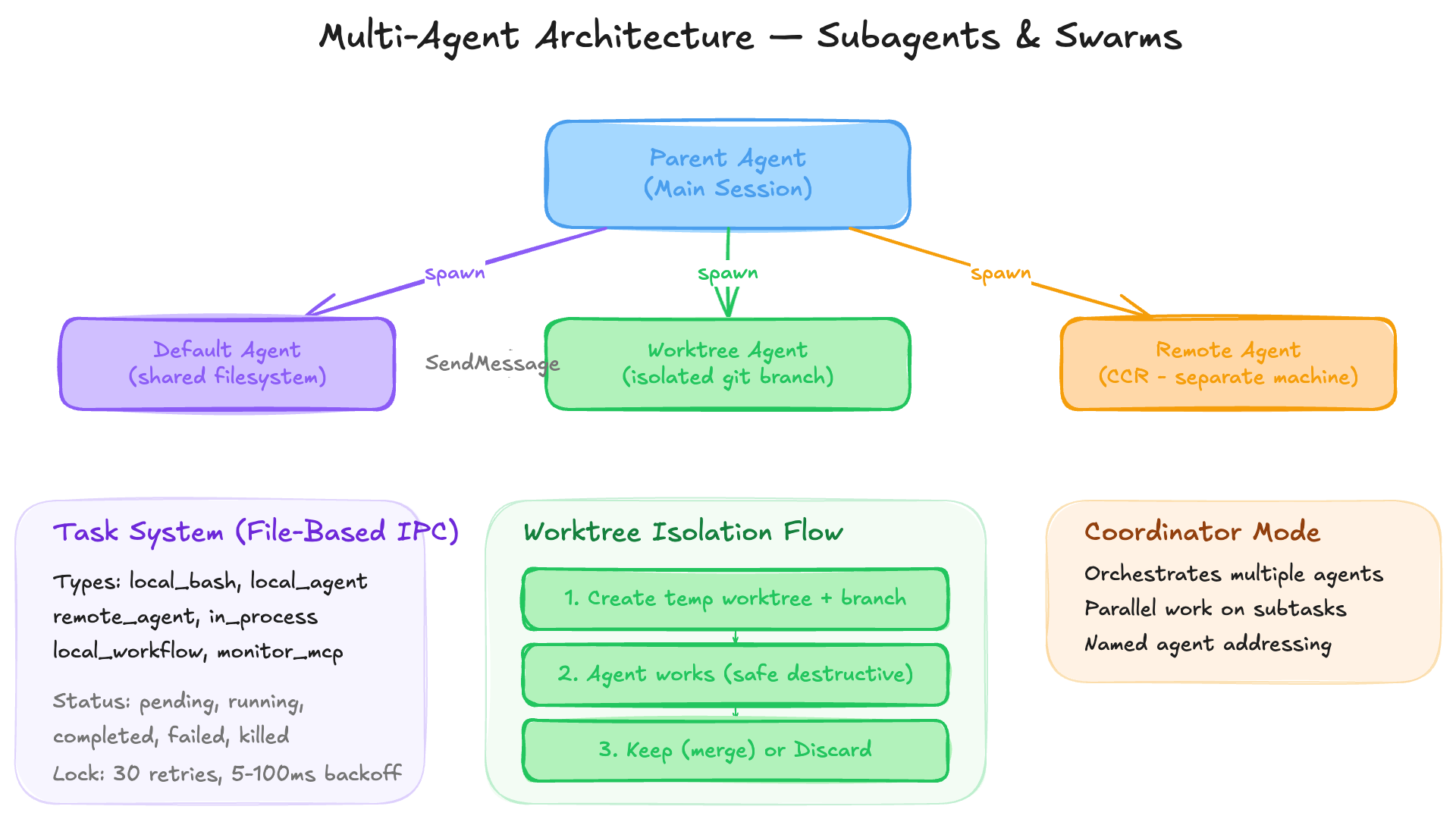
13.1 Agent Spawning
The AgentTool spawns child agents with configurable isolation:
Default — Shared filesystem, separate conversation context
Worktree — Isolated git branch copy, changes merged on exit
Remote (CCR) — Runs on a separate machine
Agents are addressable by name:
Model: "Ask the test-runner agent to run the suite"
→ SendMessage(to: "test-runner", message: "Run the test suite")
13.2 Task System
Background tasks use file-based IPC with concurrent-session locking:
Indefinite 429/529 retries with max 5-minute backoff
30-second heartbeat keep-alive messages
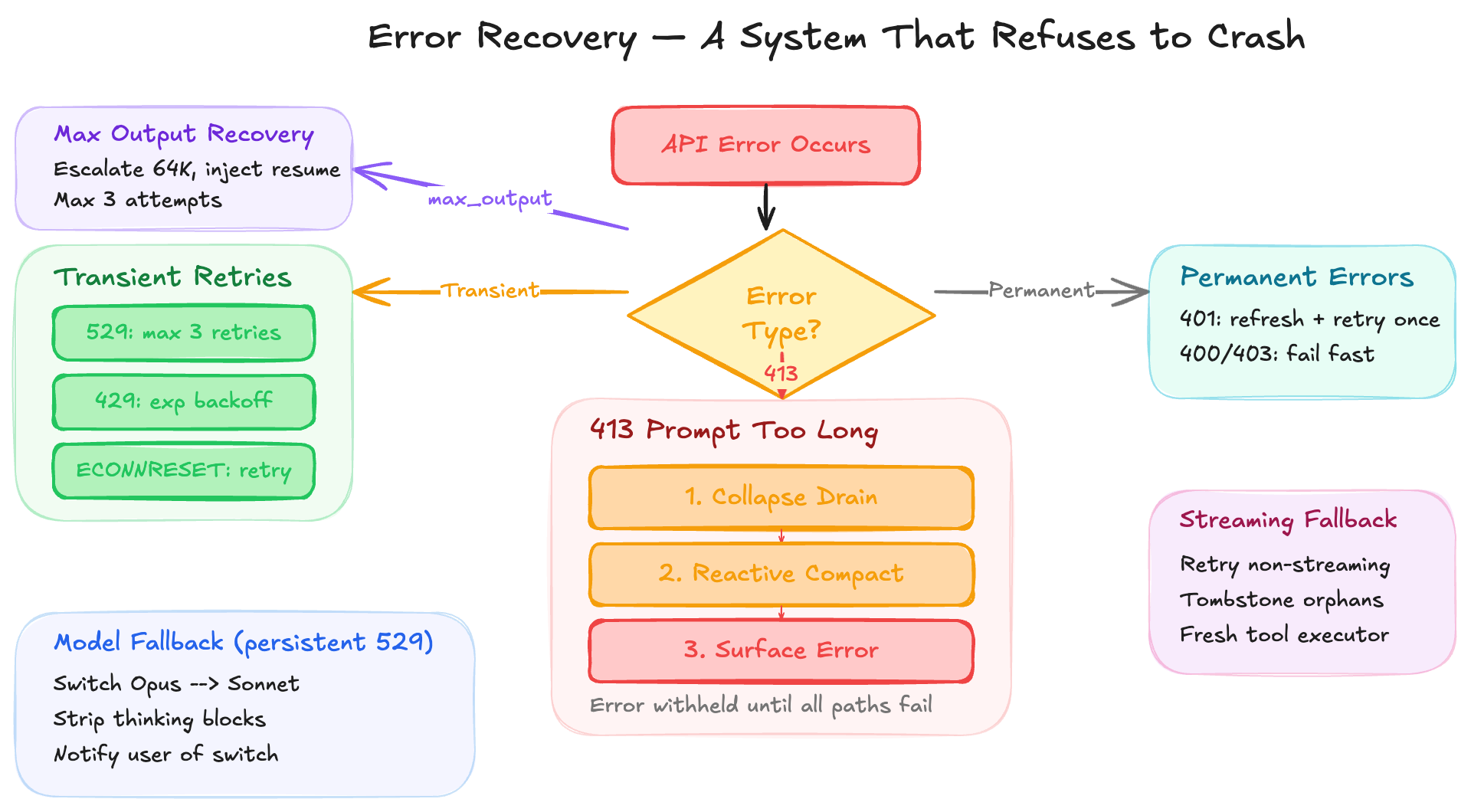
14.2 Prompt-Too-Long Recovery
When the API returns 413:
413 Prompt Too Long
├─ 1. Collapse drain (commit staged context collapses)
├─ 2. Reactive compact (generate full conversation summary)
└─ 3. Surface error if all paths exhausted
The error is withheld from the SDK until recovery paths are exhausted — the user never sees a 413 if compaction can resolve it.
14.3 Max Output Tokens Recovery
max_output_tokens stop reason
├─ 1. Escalate to 64K tokens (once per turn)
├─ 2. Inject meta recovery message ("Resume directly")
├─ 3. Max 3 attempts before surfacing
└─ 4. Withhold intermediate errors
14.4 Model Fallback
On persistent 529 errors:
Switch to fallback model (e.g., Sonnet when Opus is overloaded)
Strip thinking blocks (model-bound signatures)
Log fallback event with chain ID
Yield system message about the switch
14.5 Streaming Fallback
If streaming fails mid-response:
Retry with non-streaming request
Tombstone orphaned messages
Clear assistant messages to restart the turn
Fresh tool executor to prevent orphan results
15. Cost Tracking and Telemetry
15.1 Usage Accumulation
Per-model tracking:
Input tokens, output tokens
Cache read/write tokens
Web search requests
USD cost (calculated via calculateUSDCost())
Advisor model costs are recursively accumulated from getAdvisorUsage().
15.2 Display
formatTotalCost() produces a multi-line report:
Total cost
Per-model breakdown
API/wall-clock duration
Lines of code changed
Unknown model cost disclaimer
15.3 Telemetry
Analytics use a decoupled sink pattern:
attachAnalyticsSink() called during startup
Events queued until sink is available (prevents import cycles)
Datadog fanout + first-party event logging
PII-tagged fields for compliance
OpenTelemetry spans for LLM request tracing
Gateway detection identifies proxy infrastructure from response headers: LiteLLM, Helicone, Portkey, Cloudflare AI Gateway, Kong, Braintrust, Databricks.
16. Execution Modes: One Codebase, Many Faces
Claude Code runs in multiple modes from a single codebase:
Interactive CLI (Default)
Full React terminal UI with REPL loop, text selection, mouse support, and rich rendering.
Non-Interactive / Headless
--print mode outputs the response to stdout. --output saves to a file. No user interaction — suitable for scripts, CI/CD, and piping.
MCP Server Mode
claude mcp serve runs Claude Code as an MCP server, exposing its tools to other MCP clients.
Bridge Mode (Claude.ai Integration)
WebSocket connection to claude.ai for remote control:
CLI sends status updates to the web UI
Web UI sends control commands back
Bidirectional message adaptation (SDK format ↔ local format)
Viewer-only mode for read-only clients
Remote / Teleport
claude remote-control exposes the CLI as a WebSocket server. Users can connect via claude.ai’s web interface or QR code.
Local Agent Mode
Subprocesses spawned for multi-agent swarms. Each agent gets its own session, AppState, and task directory. Communication via file I/O.
Coordinator Mode
Orchestrates multiple agents working in parallel on different aspects of a task. (See dedicated section below.)
17. BUDDY: A Tamagotchi-Style AI Pet
One of the most surprising finds in the codebase: a fully implemented Tamagotchi-style virtual companion that lives beside the user’s input box. What started as an April Fools feature (teaser window: April 1-7, 2026) became a real, permanent feature.
17.1 How Your Buddy Is Born
Every companion is deterministically generated from the user’s account ID using a Mulberry32 seeded PRNG:
// Mulberry32 — tiny seeded PRNG, good enough for picking ducksfunctionmulberry32(seed:number):()=>number{leta=seed>>>0returnfunction(){a|=0a=(a+0x6d2b79f5)|0lett=Math.imul(a^(a>>>15),1|a)t=(t+Math.imul(t^(t>>>7),61|t))^treturn((t^(t>>>14))>>>0)/4294967296}}
The seed is hash(userId + 'friend-2026-401'). This means your companion is unique to you but identical across devices and sessions — you always get the same one.
Species names are encoded as String.fromCharCode(0x64,0x75,0x63,0x6b) rather than string literals to avoid tripping an excluded-strings build check (one species name collides with a model codename).
Rarity tiers (weighted random):
Tier
Weight
Stat Floor
Hat?
Common
60%
5
None
Uncommon
25%
15
Random
Rare
10%
25
Random
Epic
4%
35
Random
Legendary
1%
50
Random
Cosmetics:
6 eye styles:·, +, x, @, °, and a special star eye
5 stats: DEBUGGING, PATIENCE, CHAOS, WISDOM, SNARK — one peak stat, one dump stat, rest scattered. Higher rarity = higher stat floors.
Each species star rating displays with themed colors: common (inactive), uncommon (green), rare (permission blue), epic (auto-accept purple), legendary (warning gold).
17.3 Soul Generation
On first “hatch,” Claude generates a unique name and personality for the companion. This is stored permanently in the user’s global config as StoredCompanion:
Critically, only the soul persists — bones (species, rarity, stats) are regenerated from the userId hash every time. This prevents users from editing their config to fake a legendary, and allows species renames without breaking stored companions.
17.4 Sprite Animation System
Each species has 3 animation frames as 5-line, 12-character-wide ASCII art:
Eye placeholders {E} are replaced with the companion’s assigned eye character at render time. Hat lines overlay the top row (only when the species’ top row is blank).
The idle sequence cycles at 500ms per tick:
constIDLE_SEQUENCE=[0,0,0,0,1,0,0,0,-1,0,0,2,0,0,0]// -1 = "blink on frame 0" (eyes temporarily replaced)
This creates a natural feel: mostly still, occasional fidgets, rare blinks.
17.5 Speech Bubbles and Interaction
The companion renders as a CompanionSprite React component positioned beside the prompt input. It features:
Speech bubbles with a SpeechBubble component using rounded borders
Bubbles display for ~10 seconds (20 ticks) then fade over the last 3 seconds
/buddy pet triggers a floating heart animation (2.5 seconds) with hearts drifting upward
The companion can react to conversation events via companionReaction in AppState
When terminal is too narrow (<100 cols), the full sprite is hidden and replaced with a compact face-only rendering
A companion intro is injected as a special attachment into the conversation, informing Claude that a small creature named X sits beside the input box and occasionally comments in bubbles.
The teaser uses local dates, not UTC — creating a rolling 24-hour wave across timezones for sustained social media buzz rather than a single UTC-midnight spike. During the teaser window, users who haven’t hatched a companion see a rainbow-colored /buddy notification.
18. KAIROS: Persistent Assistant Mode and Auto-Dreaming
KAIROS (feature-flagged as KAIROS) is a complete alternate UX where Claude becomes a long-lived autonomous agent that persists across sessions — the “Always-On Claude.”
18.1 Auto-Dreaming: Memory Consolidation
The most concrete KAIROS subsystem in the codebase is the auto-dream system (services/autoDream/). This is a background memory consolidation agent that runs as a forked subagent.
Gate order (cheapest checks first):
Time gate: Hours since last consolidation >= minHours (default: 24h)
Session gate: Number of transcript sessions since last consolidation >= minSessions (default: 5)
Lock gate: No other process is mid-consolidation (file lock with mtime-based conflict detection)
Scan throttle: Even when the time gate passes, session scanning is throttled to every 10 minutes
The 4-phase dream prompt:
Phase 1 — Orient
└─ ls the memory directory, read the index, skim existing topic files
Phase 2 — Gather recent signal
└─ Check daily logs, find drifted memories, grep transcripts narrowly
Phase 3 — Consolidate
└─ Write/update memory files, merge duplicates, convert relative dates
Phase 4 — Prune and index
└─ Update the entrypoint index (max ~25KB), remove stale pointers
Tool constraints for dream runs: Bash is restricted to read-only commands only — ls, find, grep, cat, stat, wc, head, tail. Write operations are denied. File edits go through the normal Edit/Write tools with permission via createAutoMemCanUseTool().
Dream task lifecycle:
typeDreamTaskState={type:'dream'phase:'starting'|'updating'// Flips when first Edit/Write landssessionsReviewing:numberfilesTouched:string[]// Paths observed in Edit/Write tool_useturns:DreamTurn[]// Last 30 assistant turns (rolling window)abortController?:AbortControllerpriorMtime:number// For lock rollback on failure}
Users can kill a running dream from the background tasks dialog (Shift+Down). On kill, the lock mtime is rewound so the next session can retry.
18.2 KAIROS Integration Points
KAIROS is referenced throughout the codebase:
getKairosActive() in bootstrap state — gates whether KAIROS mode is active
Auto-dream is disabled in KAIROS mode (KAIROS uses its own disk-skill dream variant)
Brief mode (BriefTool) — all output goes through SendUserMessage tool (structured markdown + attachments + status)
Proactive <tick> prompts — periodic check-ins where Claude decides what to do next
15-second blocking budget — commands exceeding 15s are auto-backgrounded
Append-only daily logs at ~/.claude/projects/<slug>/memory/logs/YYYY/MM/YYYY-MM-DD.md
Midnight boundary handling — flushes yesterday’s transcript on date change so the dream process can find it
18.3 Session History (Assistant Mode)
assistant/sessionHistory.ts provides paginated session event retrieval for KAIROS:
typeHistoryPage={events:SDKMessage[]firstId:string|null// Cursor for next-older pagehasMore:boolean}
Uses OAuth-authenticated API calls to CCR (Claude Code Remote) to fetch session transcripts. Pagination goes backwards (newest → oldest) with 100 events per page and 15-second timeout per request.
19. ULTRAPLAN: Remote Planning Sessions
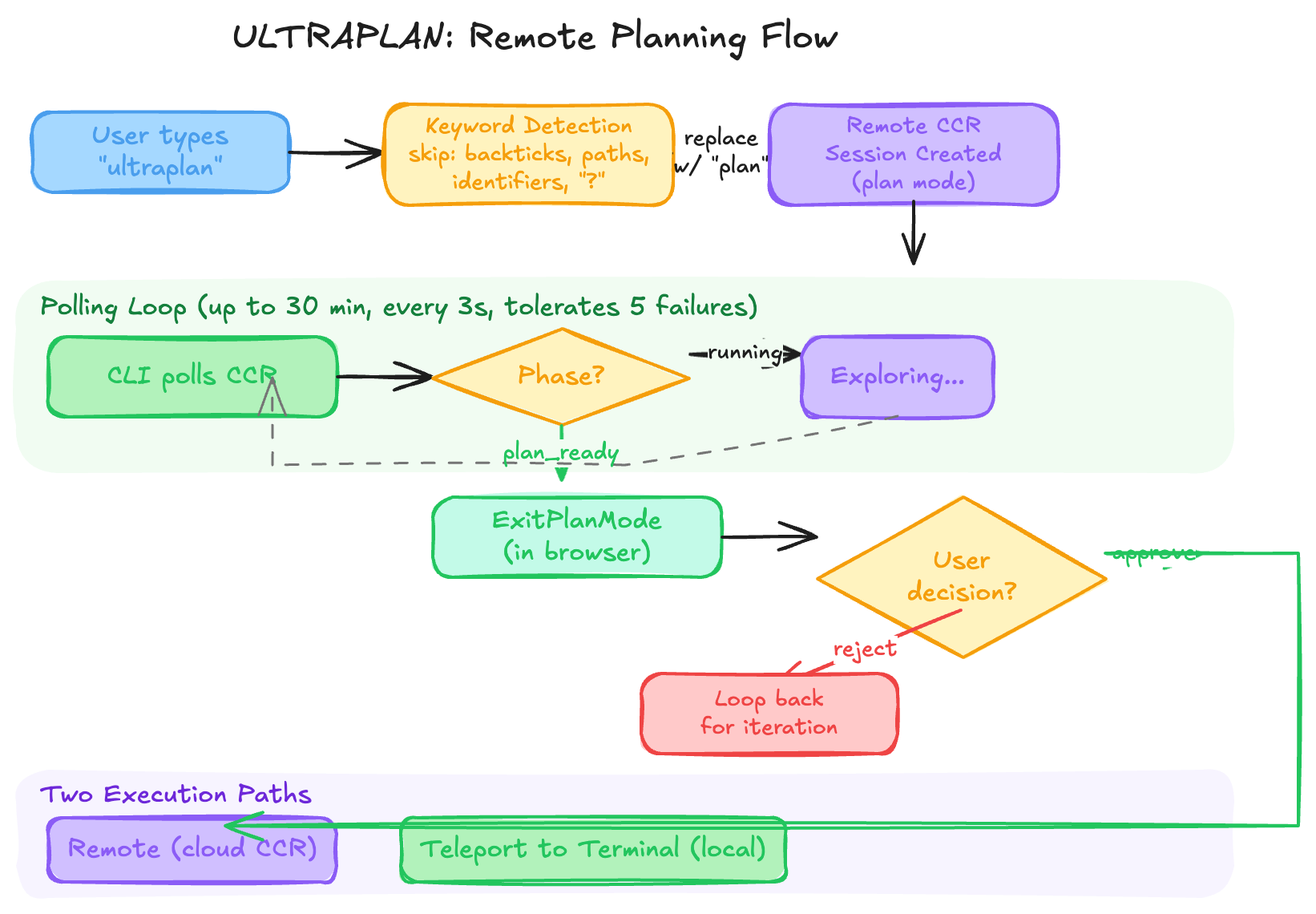
ULTRAPLAN is an interactive planning system that farms out complex exploration to a remote Claude Code instance (CCR) for up to 30 minutes.
19.1 How It Works
User types “ultraplan” (keyword detection, not slash command) or uses /ultraplan
A remote CCR session is created with plan mode pre-configured
The CLI polls the remote session every 3 seconds for up to 30 minutes
Remote Claude explores, plans, and calls ExitPlanMode when ready
User approves or rejects the plan in the browser (claude.ai)
Rejected plans loop back for iteration
19.2 Keyword Detection
The keyword trigger system (utils/ultraplan/keyword.ts) is remarkably sophisticated. It finds “ultraplan” in user input while avoiding false positives:
Followed by ? (questions about the feature shouldn’t invoke it)
Slash command input (/rename ultraplan foo runs /rename, not ultraplan)
When triggered, “ultraplan” is replaced with “plan” in the forwarded prompt to keep it grammatical: "please ultraplan this" → "please plan this".
19.3 Two Execution Paths on Approval
On approval, the user chooses one of two paths:
Path
What Happens
“remote”
Execute the plan in the cloud CCR instance
“teleport to terminal”
Archive the remote session, execute locally
The teleport path uses a sentinel string __ULTRAPLAN_TELEPORT_LOCAL__ embedded in the browser’s rejection feedback. The rejection keeps the remote in plan mode, but the plan text is extracted from the feedback and executed locally.
19.4 Event Stream Scanning
The ExitPlanModeScanner class is a pure stateful classifier for the CCR event stream:
Resilience: The poller tolerates up to 5 consecutive network failures before aborting (a 30-minute poll makes ~600 API calls — at any nonzero failure rate, one blip is inevitable).
20. Coordinator Mode: Multi-Agent Orchestrator
Coordinator Mode (CLAUDE_CODE_COORDINATOR_MODE=1) transforms Claude Code from a single-agent assistant into a multi-agent orchestrator where a master coordinator directs multiple parallel workers.
20.1 Architecture
Coordinator (you)
├─ AgentTool → Worker A (research) ─┐
├─ AgentTool → Worker B (research) ─┤ Run in parallel
├─ AgentTool → Worker C (implement) ─┘
└─ SendMessage → Continue Worker A with synthesized spec
The coordinator’s system prompt enforces a strict discipline:
“Never write ‘based on your findings’“ — the coordinator must synthesize worker research into specific specs with file paths, line numbers, and exactly what to change
Workers report back as XML <task-notification> messages with status, summary, result, and usage
The coordinator never polls — workers push completion notifications
Workers get isolated scratch directories (via tengu_scratch feature gate) for durable cross-worker knowledge
20.2 Worker Capabilities
Workers spawned via AgentTool have access to standard tools (or a simplified Bash/Read/Edit set in CLAUDE_CODE_SIMPLE mode), plus MCP tools from configured servers. The coordinator injects a workerToolsContext into the system prompt listing exactly which tools workers can use.
20.3 Task Workflow
The coordinator system prompt defines four phases:
Phase
Who
Purpose
Research
Workers (parallel)
Investigate codebase, find files
Synthesis
Coordinator
Read findings, craft implementation specs
Implementation
Workers
Make changes per spec, commit
Verification
Workers
Prove the code works (not just confirm it exists)
Concurrency rules:
Read-only tasks (research) — run in parallel freely
Write-heavy tasks (implementation) — one at a time per set of files
Verification — can run alongside implementation on different file areas
20.4 Continue vs. Spawn
The system provides explicit guidance on when to continue an existing worker vs. spawn fresh:
Situation
Mechanism
Reason
Research explored the exact files to edit
Continue
Worker already has files in context
Research was broad, implementation is narrow
Spawn fresh
Avoid exploration noise
Correcting a failure
Continue
Worker has error context
Verifying another worker’s code
Spawn fresh
Verifier needs fresh eyes
Wrong approach entirely
Spawn fresh
Wrong context pollutes retry
20.5 Session Mode Matching
When resuming a session, coordinator mode is automatically matched to the stored session mode:
exportfunctionmatchSessionMode(sessionMode:'coordinator'|'normal'|undefined):string|undefined{// If current mode doesn't match the resumed session, flip the env varif(sessionIsCoordinator){process.env.CLAUDE_CODE_COORDINATOR_MODE='1'}else{deleteprocess.env.CLAUDE_CODE_COORDINATOR_MODE}}
This prevents a normal session from being resumed in coordinator mode (or vice versa), which would cause confusion.
21. The Memory System: Persistent AI Memory
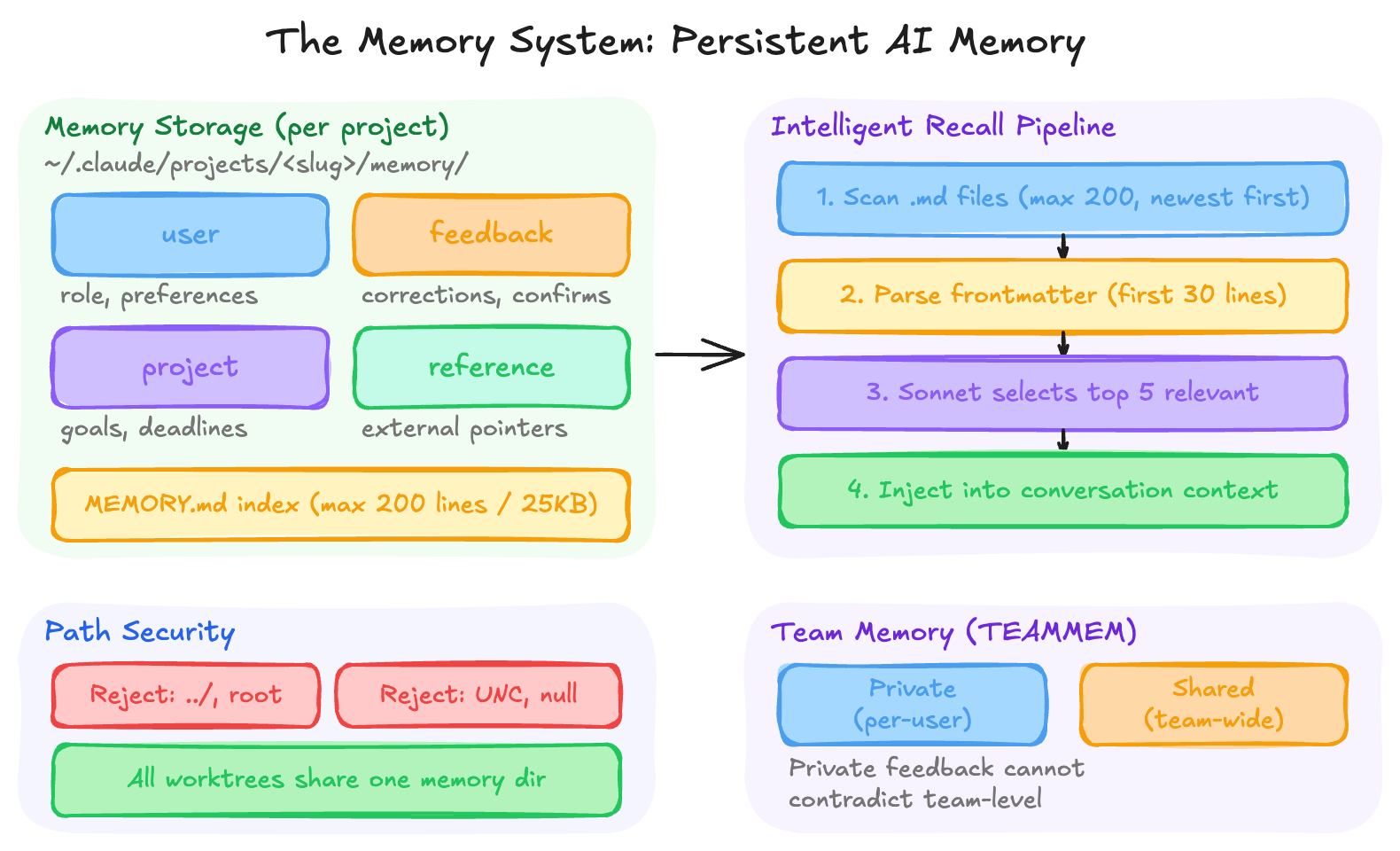
Claude Code has a sophisticated file-based memory system (memdir/) that allows it to remember context across conversations — user preferences, project knowledge, feedback, and reference pointers.
21.1 Memory Architecture
Memories are stored as individual markdown files with YAML frontmatter at ~/.claude/projects/<sanitized-project-root>/memory/:
---name:user_roledescription:User is a senior backend engineer focused on Rusttype:user---
User is a senior backend engineer at Acme Corp, primarily works in Rust...
An index file MEMORY.md (max 200 lines / 25KB) serves as a table of contents — it’s loaded into every conversation’s system prompt so Claude knows what memories exist without reading them all.
21.2 Four Memory Types
Type
Purpose
Example
user
Role, preferences, knowledge level
“User is a data scientist, new to React”
feedback
How to approach work (corrections + confirmations)
“Don’t mock the database in integration tests”
project
Ongoing work, goals, deadlines
“Merge freeze begins 2026-03-05 for mobile release”
reference
Pointers to external systems
“Pipeline bugs tracked in Linear project INGEST”
The system explicitly does NOT save: code patterns, architecture, git history, debugging solutions, or anything derivable from the current project state.
21.3 Intelligent Memory Recall
Not all memories are loaded every turn. Instead, a Sonnet-powered relevance selector (findRelevantMemories.ts) runs as a side query:
Scan all .md files in the memory directory (max 200, newest-first)
Parse frontmatter headers (name, description, type) from the first 30 lines
Send the user’s query + memory manifest to Sonnet with structured JSON output
Sonnet returns up to 5 most relevant filenames
Those files are injected into the conversation context
A clever optimization: recently-used tools are passed to the selector so it skips reference docs for tools Claude is already exercising (e.g., don’t surface MCP spawn docs when Claude is actively using the spawn tool).
21.4 Path Security
The memory path system includes robust security validation:
projectSettings (committed to repo) is intentionally excluded from autoMemoryDirectory — a malicious repo could otherwise set autoMemoryDirectory: "~/.ssh" and gain write access to sensitive directories
All worktrees of the same git repo share one memory directory (via findCanonicalGitRoot)
CLAUDE_COWORK_MEMORY_PATH_OVERRIDE for SDK/Cowork integration
21.5 Team Memory
When the TEAMMEM feature is enabled, memories split into private (per-user) and team (shared) directories. User preferences stay private; project conventions and reference pointers default to team scope. A conflict rule prevents private feedback memories from contradicting team-level ones.
22. Hooks: User-Defined Automation
The hooks system (schemas/hooks.ts) lets users attach automated behaviors to Claude Code events — shell commands, LLM prompts, HTTP calls, or agent verifiers that fire before/after tool use, message submission, and more.
Command hooks run shell commands with optional timeout, async/background execution, and one-shot mode (once: true — runs once then auto-removes).
Prompt hooks evaluate an LLM prompt with $ARGUMENTS placeholder for the hook input JSON.
HTTP hooks POST the hook input to a URL with configurable headers and env var interpolation (only explicitly-allowed env vars are resolved — prevents leaking secrets).
Agent hooks run a full agentic verification loop (“Verify that unit tests ran and passed”) with configurable model and timeout.
22.2 Event-Matcher-Hook Pipeline
Hooks are configured in settings.json as a three-level structure:
Event → Matcher[] → Hook[]
Each event (PreToolUse, PostToolUse, PreMessage, PostMessage, etc.) has an array of matchers with optional permission-rule-syntax patterns (e.g., "Bash(git *)" — only fires for git commands). Each matcher has an array of hooks to execute.
The if condition field uses the same permission rule syntax as the tool permission system, evaluated against tool_name and tool_input — so hooks can fire selectively without spawning a process for every tool call.
22.3 Advanced Hook Features
async: true — Hook runs in background without blocking the model
asyncRewake: true — Runs in background but wakes the model on exit code 2 (blocking error)
once: true — Auto-removes after first execution (useful for one-time setup)
statusMessage — Custom spinner text while the hook runs
Environment variable interpolation in HTTP headers with explicit allowlist
23. Voice Mode, Bridge, and Infrastructure
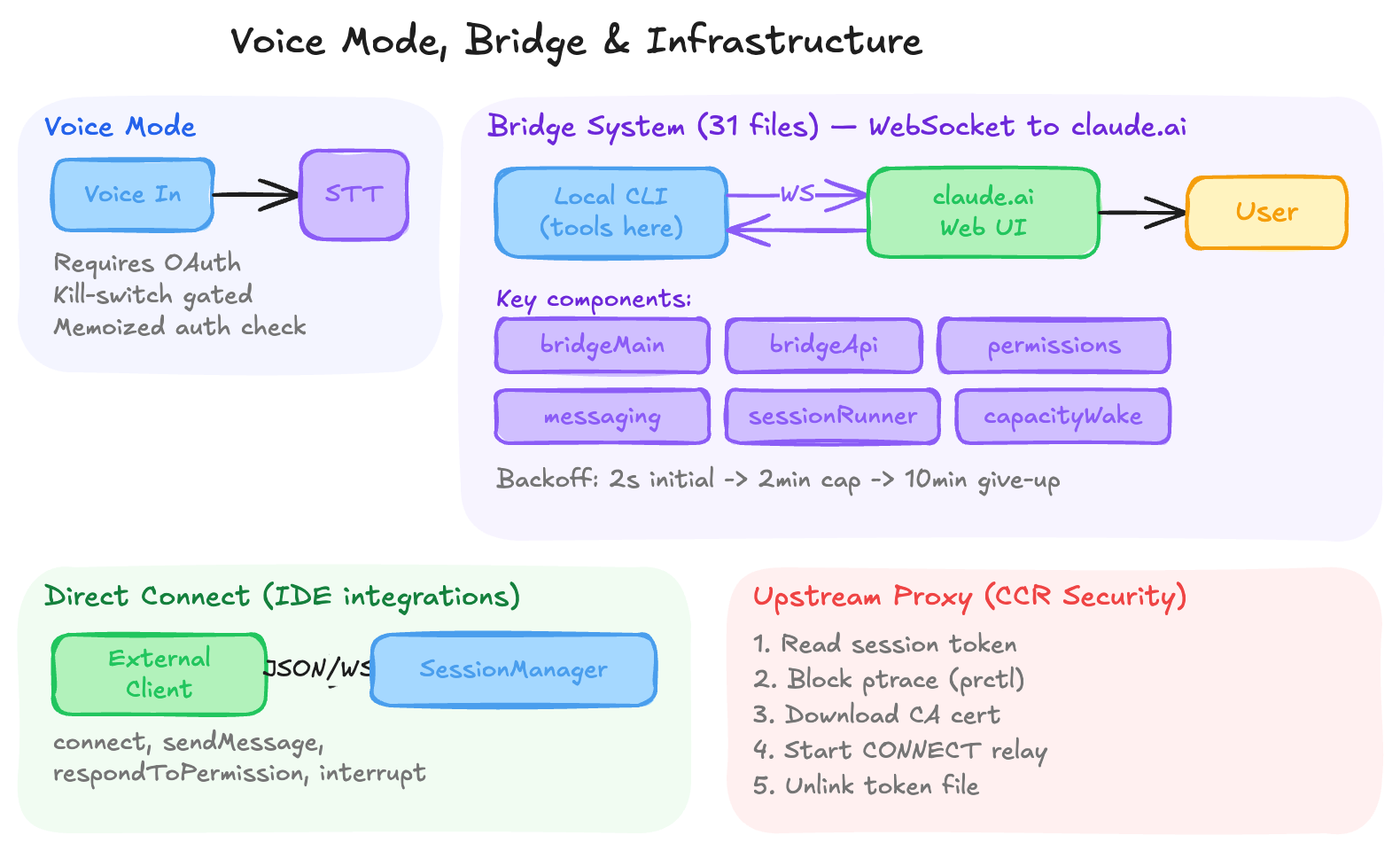
23.1 Voice Mode
Claude Code includes a voice input mode (feature-flagged as VOICE_MODE) that allows voice-to-text interaction:
Requires Anthropic OAuth (not API keys, Bedrock, or Vertex) — uses the voice_stream endpoint on claude.ai
Protected by a GrowthBook kill-switch (tengu_amber_quartz_disabled) for emergency off
Auth check uses memoized keychain reads (~20-50ms first call, cache hit thereafter)
The /voice command, ConfigTool, and a VoiceModeNotice component all gate on isVoiceModeEnabled()
23.2 The Bridge System (31 Files)
The bridge (bridge/) is the most substantial networking subsystem — a persistent WebSocket connection between the local CLI and claude.ai’s web interface (CCR). It enables using Claude Code from a browser while the actual tools execute locally.
Key components:
bridgeMain.ts — Main bridge loop with exponential backoff (2s initial → 2min cap → 10min give-up)
bridgeApi.ts — API client with JWT refresh, trusted device tokens, session validation
bridgeMessaging.ts / inboundMessages.ts — Message adaptation (SDK format ↔ local format)
bridgePermissionCallbacks.ts — Permission request mediation between web UI and local CLI
sessionRunner.ts — Spawns agent sessions per work item, manages worktrees
capacityWake.ts — Wakes idle bridge when capacity becomes available
workSecret.ts — Encrypted work routing between bridge workers
The bridge handles session lifecycle, token refresh, trusted device enrollment, and graceful reconnection — essentially a mini-RPC framework over WebSocket.
23.3 Direct Connect
The server/ directory implements Direct Connect — a WebSocket-based protocol for external clients to connect to a running Claude Code instance:
classDirectConnectSessionManager{connect():void// Open WebSocketsendMessage(content):boolean// Send user messagerespondToPermissionRequest(...)// Handle tool permission promptssendInterrupt():void// Cancel current requestdisconnect():void// Close connection}
Messages are JSON-over-WebSocket using the SDK message format. Control requests (permission prompts) are forwarded to the client, which responds with allow/deny decisions. This enables IDE integrations and custom frontends.
23.4 Upstream Proxy (CCR Security)
When running inside a CCR container, the upstream proxy system (upstreamproxy/) provides secure network access:
Read session token from /run/ccr/session_token
Set prctl(PR_SET_DUMPABLE, 0) — blocks same-UID ptrace (prevents prompt-injected gdb -p $PPID from scraping the token off the heap)
Download CA certificate and concatenate with system bundle for MITM proxy trust
Start local CONNECT→WebSocket relay on a random port
Unlink the token file (token stays heap-only; file is gone before the agent loop can access it)
Inject HTTPS_PROXY / SSL_CERT_FILE env vars for all subprocesses
Every step fails open — a broken proxy never breaks an otherwise-working session. The NO_PROXY list covers loopback, RFC1918, IMDS, Anthropic API, GitHub, and package registries.
23.5 Output Styles
The outputStyles/ system lets users customize Claude’s response format via markdown files:
Project styles: .claude/output-styles/*.md
User styles: ~/.claude/output-styles/*.md
Plugin styles: provided by installed plugins
Each style file has frontmatter (name, description, keep-coding-instructions) and a prompt body that shapes how Claude formats its responses.
23.6 Native TypeScript Modules
native-ts/ contains TypeScript bindings for performance-critical native code:
yoga-layout/ — TypeScript interface to the Yoga layout engine (flexbox calculations)
file-index/ — Native file indexing for fast codebase search
color-diff/ — Native color difference calculations (for theme/styling)
23.7 Moreright (Internal-Only)
The moreright/ directory contains a stub for an internal-only feature. The external build ships a no-op implementation with onBeforeQuery, onTurnComplete, and render all returning trivially. The real implementation is internal to Anthropic.
24. Vim Mode, Keybindings, and Developer Ergonomics
24.1 Vim Mode
A full vi command system:
Motions — h, j, k, l, w, b, e, 0, $, gg, G
Operators — d (delete), c (change), y (yank)
Text Objects — iw (inner word), ap (a paragraph)
Modal State Machine — Insert, Normal, Visual modes
All compiled to a single-pass command matcher for low-latency input processing.
Users can define chord bindings: ctrl+k ctrl+o maps to custom actions via ~/.claude/keybindings.json.
24.3 Debug Tools
CLAUDE_CODE_DEBUG_REPAINTS=1 — Shows component owner chain for every repaint
CLAUDE_CODE_COMMIT_LOG=/tmp/commits.log — Logs slow renders for profiling
CLAUDE_CODE_PROFILE_STARTUP=1 — Full startup profiling with memory snapshots
25. Key Engineering Patterns and Takeaways
Pattern 1: Lazy Everything
Claude Code is aggressive about deferral:
Lazy schemas — Zod instantiation deferred via lazySchema()
Lazy commands — Module imports via load() functions
Lazy tools — 18 tools deferred to ToolSearchTool
Lazy modules — Dynamic imports for OpenTelemetry, analytics, heavy components
Lazy bundled skills — Reference files extracted on first use
Pattern 2: Memoization by Identity
Key functions are memoized to prevent redundant work:
COMMANDS() — Memoized, cleared by clearCommandMemoizationCaches()
loadAllCommands(cwd) — Memoized by working directory
init() — Memoized to prevent re-entrancy
Pattern 3: Feature Flags for Dead Code Elimination
Bun’s feature() function enables compile-time dead code elimination:
if(feature('COORDINATOR_MODE')){// This entire block is removed from the binary when the flag is offconst{CoordinatorUI}=awaitimport('./coordinator/index.js')}
Pattern 4: Interning for Performance
Three interning pools (chars, styles, hyperlinks) reduce memory and enable O(1) comparison by integer ID instead of string equality. The style pool even pre-computes ANSI transition sequences.
Pattern 5: Fail-Closed Security
The buildTool() factory provides safe defaults for 7 commonly-stubbed methods. Permissions default to “ask” — a tool must explicitly opt into auto-approval.
Pattern 6: Centralized Side Effects
onChangeAppState() is the single choke point for all state mutations that affect external systems. No scattered useEffect side effects.
Pattern 7: File-Based IPC
Multi-agent coordination uses files, not sockets:
Task outputs in ~/.claude/
History in ~/.claude/history.jsonl
Session transcripts for resume
Lock files with retry backoff for concurrent access
Pattern 8: Prompt Cache Stability
Tools are sorted alphabetically before being sent to the API. This keeps the tool list in the same order across requests, maximizing prompt cache hit rates.
Pattern 9: Progressive Disclosure
The deferred tool system implements progressive disclosure at the API level:
Base prompt stays under 200K tokens
Model discovers additional tools on demand via ToolSearchTool
Discovered tools are callable in the same turn
Pattern 10: Three-Tier Configuration
Settings are resolved from multiple sources with clear precedence:
MDM Policy (highest) → Remote Managed → User Settings
→ Project Config → Global Config → Defaults (lowest)
26. Conclusion
Claude Code is a remarkable piece of engineering. What appears to the user as a simple chat interface in the terminal is backed by:
A custom React reconciler with Yoga layout, double-buffered rendering, and hardware scroll optimization
A resilient query engine with automatic context compression, multi-strategy error recovery, and token budget continuation
A 60+ tool ecosystem unified under a single generic interface with Zod validation, lazy schemas, and elastic discovery
A multi-layered permission system balancing security and developer productivity across 5 modes, rule patterns, and ML classifiers
An extensibility framework spanning skills, plugins, and MCP with 8 configuration scopes and 5 transport types
The codebase demonstrates that a CLI tool can be as architecturally sophisticated as any web application — perhaps more so, given the unique constraints of terminal rendering, keyboard input ambiguity, and the need to coordinate an AI model, file system, shell, and git repository all within a single conversation loop.
For developers building similar tools, the key lessons are:
Invest in the rendering layer. Claude Code’s custom Ink framework is its competitive advantage for terminal UX.
Design for failure. The multi-strategy error recovery (compaction → collapse → fallback → surface) means users almost never see raw API errors.
Defer aggressively. Lazy loading at every level — schemas, modules, tools, skills — keeps startup fast and memory bounded.
Intern everything. Style pools, character pools, and hyperlink pools turn O(n) string comparisons into O(1) integer comparisons.
Make safety the default. Fail-closed permissions, dangerous pattern detection, and mandatory confirmation for destructive operations build user trust.
Claude Code isn’t just a wrapper around an API. It’s a complete development environment that happens to run in your terminal.
This analysis is based on examination of the Claude Code source code. All technical details reflect the codebase as observed at the time of analysis.
]]>Sathwicksathwick.p7@gmail.comClaude Code’s Hidden Features: Undocumented, Gated, and Internal Capabilities2026-03-31T00:00:00+00:002026-03-31T00:00:00+00:00https://sathwick.xyz/blog/claude-hiddenGenuinely hidden, gated, or underdocumented capabilities found in the source code — things the public docs don’t cover.
Based on direct source inspection. “Hidden” = hidden from --help, feature-flagged, or dependent on non-public backends. Source presence does not guarantee your build/account has access.
Deprecated aliases (still work): --afk and --dangerously-skip-permissions-with-classifiers → map to --enable-auto-mode
Correction:--voice is NOT a CLI flag. Voice is activated via /voice slash command or the voiceEnabled setting. --brief and --proactive are not hidden — they appear in help when their feature flags are on.
2. Feature-Gated Slash Commands
These commands exist but are conditionally registered or hidden:
Command
What It Does
Gate
/buddy
Hatch and interact with a Tamagotchi-style AI pet
BUDDY flag + date gate
/voice
Toggle hold-to-talk voice dictation
VOICE_MODE + Anthropic OAuth
/advisor [model\|off]
Attach/detach a secondary reviewer model
GrowthBook tengu_sage_compass
/fast [on\|off]
Toggle fast inference mode
Available when fast mode is supported
/dream
Manually trigger memory consolidation
Auto-memory must be enabled
/brief
Toggle brief/checkpoint mode
KAIROS or KAIROS_BRIEF
/ultraplan
Launch a remote 30-minute planning session
ULTRAPLAN feature flag
/heapdump
Dump JavaScript heap to ~/Desktop
Always registered, hidden
/thinkback
2025 Claude Code year-in-review stats
GrowthBook tengu_thinkback
/remote-control (alias /rc)
Enter bridge mode
BRIDGE_MODE
3. The Buddy System — A Full Tamagotchi Pet
A fully implemented virtual companion that lives beside your input box.
Activate:/buddy
Deterministic generation from your userId via Mulberry32 PRNG — same user = same companion across all devices
Compile-time flags via feature() from bun:bundle. When off, code is eliminated entirely from the binary:
Flag
Feature
COORDINATOR_MODE
Multi-agent coordinator
VOICE_MODE
Voice input
KAIROS / KAIROS_BRIEF
Persistent assistant mode
PROACTIVE
Autonomous mode
BRIDGE_MODE
Remote control bridge
SSH_REMOTE
SSH remote execution
DIRECT_CONNECT
cc:// URL handling
BG_SESSIONS
Background sessions
TEMPLATES
Template/new/reply flows
TEAMMEM
Team memory sync
TRANSCRIPT_CLASSIFIER
AI permission classification
BUDDY
Tamagotchi pet
ULTRAPLAN
Remote planning
EXTRACT_MEMORIES
Auto-memory extraction
WORKFLOW_SCRIPTS
Workflow automation
QUICK_SEARCH
Quick search (Ctrl+Shift+F)
TERMINAL_PANEL
Terminal panel (Meta+J)
MESSAGE_ACTIONS
Message action menu (Shift+Up)
CONTEXT_COLLAPSE
Context collapse optimization
HISTORY_SNIP
History snipping
MCP_SKILLS
MCP skill discovery
DAEMON
Long-running daemon
Compiled from static analysis of the Claude Code source. Corrections applied from the audited version. Features behind flags may not be in your build.
]]>Sathwicksathwick.p7@gmail.comDesigning a URL Shortener for 1 Trillion URLs2026-03-08T00:00:00+00:002026-03-08T00:00:00+00:00https://sathwick.xyz/blog/bitlyI’ve read multiple system design books, taken courses, and watched several playlists on YouTube. One of the most common and foundational system design questions that almost everyone starts with is the Bitly problem: designing a URL shortener that converts long URLs into shorter, more manageable links.
Over time, this question started to feel dry and repetitive. I often found myself skipping it whenever I saw it again.
Recently, though, I came across a very interesting variation of the problem. I tried designing a solution for it, and that is what inspired me to write this post.
The Challenge
The challenge is to design a URL shortener that supports 1 trillion URLs.
At first glance, this sounds like a simple scaling problem, but it actually changes a lot of things and breaks many of the naive assumptions that usually work for the standard Bitly-style system design question.
Even if we assume a base-62 encoding (0-9, a-z, A-Z), a 7-character string gives us roughly 3.5 trillion possible combinations.
That sounds like plenty for 1 trillion URLs, but things get complicated once we start thinking about distribution, storage, and collision guarantees.
Also, 62^7 is only the raw theoretical namespace. In practice, the usable space is smaller because some codes will be reserved for custom aliases, blocked words, internal testing, and occasionally wasted ranges from crashed allocators. The margin is still comfortable, but it is not infinite.
Constraints
The shortened URL can have at most 7 characters.
The system must guarantee unique URLs with no collisions.
The system must support 1 trillion URLs over its entire lifetime.
Before diving into the trillion-URL challenge, let’s first revisit the standard approach used to solve the traditional URL shortener design problem.
The Traditional Approach
Functional Requirements
Core requirements
Users should be able to submit a long URL and receive a shortened version.
Optionally, users should be able to specify a custom alias for their shortened URL, i.e. www.short.ly/my-custom-alias.
Optionally, users should be able to specify an expiration date for their shortened URL.
Users should be able to access the original URL by using the shortened URL.
Below the line (out of scope)
User authentication and account management.
Analytics on link clicks, such as click counts or geographic data.
Non-Functional Requirements
Core requirements
The system should ensure uniqueness for short codes, where each short code maps to exactly one long URL.
Redirection should occur with minimal delay, ideally under 100 ms.
The system should be reliable and available 99.99% of the time, with availability prioritized over consistency.
The system should scale to support 1 billion shortened URLs and 100 million DAU.
Below the line (out of scope)
Real-time consistency for analytics.
Advanced security features such as spam detection and malicious URL filtering.
High-Level Design
We’ll go through the functional requirements one by one and design a system that satisfies them.
1. Submitting a long URL and receiving a short URL
When a user submits a long URL, the client sends a POST request to /urls with the long URL, custom alias, and expiration date.
The flow looks like this:
The primary server receives the request and validates the long URL format using libraries like is-url or simple validation logic.
Optionally, we can check whether this exact long URL was already shortened and return the existing short code as a deduplication optimization.
In practice, most URL shorteners allow multiple short codes for the same long URL, since different users may want different expiration dates, separate analytics, or different custom aliases.
If the URL is valid, we generate a short code and store the mapping.
Generating the short code
The standard answer is to use a hash function that produces enough randomness to make collisions unlikely.
A hash function like MD5 takes an input and produces a deterministic fixed-size output. That means the same long URL would always map to the same hash, which is useful if you want deterministic code generation.
But the system still needs to store the redirect mapping, because a hash is not reversible and we still need metadata such as expiration dates, ownership, and custom aliases.
It is also not desirable if you need multiple short codes for the same URL.
Hash outputs also have high entropy, which makes them appear random. We can encode that output using base-62 and take the first 7 characters as our shortcode.
Here, encoding simply means converting binary hash output into a sequence of readable characters from a chosen alphabet so it can be used as a short, URL-friendly code.
This gives us approximately 62^7 = 3.52 trillion possible values, which is a large namespace.
But a large namespace does not make random or truncated-hash generation safe. If the code space has size |S| and n codes are already in use, the probability that the next random code collides is n / |S|. That means you still need retries and database checks to enforce uniqueness. In a space of this size, even a system that creates around 1 billion links would expect on the order of 10^5 colliding pairs unless it performs uniqueness checks.
At more ordinary scale, a more production-friendly baseline is to stop relying on random hashes and use a centralized counter instead. Redis is a good fit here because INCR is atomic and hands out unique integers efficiently. We can base-62-encode each integer into a short code and guarantee uniqueness without a retry loop.
Even if links expire, we usually do not recycle short codes. Reusing codes creates ugly edge cases with stale caches, delayed clients, and old analytics data, so it is safer to treat the namespace as append-only over the system’s lifetime.
Once we have the short URL, we can insert it into the database along with the long URL, optional custom alias, and expiration date. Finally, we return the shortened URL to the client.
2. Accessing the original URL from the shortened URL
Once the short URL is live, users can use it to reach the original URL. Importantly, that shortened URL exists under a domain we own.
When a user accesses a shortened URL, the flow looks like this:
The browser sends a GET request with the short code, for example GET /abc123.
The primary server looks up the short code in the database.
If the short code exists and has not expired, the server retrieves the long URL. If it has expired, the server returns 410 Gone.
The server responds with an HTTP redirect, usually either 301 or 302.
For a URL shortener, a 302 redirect is often preferred because:
It gives us more control over the redirection process, allowing us to update or expire links later.
It prevents browsers from aggressively caching the redirect.
It still allows us to track click statistics, even though analytics are out of scope for this design.
How do we make redirects fast?
A naive database lookup could devolve into a full table scan, which is clearly too slow.
A better baseline is to add an index, or simply make the shortened URL the primary key. That gives us indexed lookups and also enforces uniqueness.
The remaining problem is SSD IOPS. A single database instance would still struggle to keep up with heavy traffic, leading to slower response times and possible timeouts.
A much better solution is to place an in-memory cache like Redis or Memcached between the server and the database. Frequently accessed mappings from short code to long URL can live in memory.
The read path then becomes:
On a cache hit, return the long URL in milliseconds.
On a cache miss, query the database, populate the cache, and return the result.
The difference in speed is significant:
Memory access time: about 100 nanoseconds (0.0001 ms)
SSD access time: about 0.1 ms
HDD access time: about 10 ms
That means memory access is roughly 1,000 times faster than SSD and 100,000 times faster than HDD.
In terms of operations per second:
Memory can support millions of reads per second.
SSDs can support roughly 100,000 IOPS.
HDDs typically support around 100 to 200 IOPS.
The only real challenge here is cache invalidation, which can get complicated when updates or deletions happen. In this system, though, the problem is smaller because shortened URLs are mostly read-heavy and rarely change.
The cache also needs time to warm up, so the first few requests for a URL may still hit the database. Since memory is limited, we also need to think carefully about cache size, eviction policies such as LRU, and which entries are worth storing.
3. Scaling the standard design to 1 billion URLs
Let’s do some rough sizing.
Each row in the database contains:
A short code, roughly 8 bytes
A long URL, roughly 100 bytes
creationTime, roughly 8 bytes
An optional custom alias, roughly 100 bytes
An expiration date, roughly 8 bytes
That totals around 200 bytes per row. If we round up to 500 bytes to account for metadata such as creator ID, analytics ID, and internal overhead, then 1 billion mappings would require:
500 bytes * 1 billion rows = 500 GB
That is still within the capabilities of modern SSDs, and if we need more headroom, we can shard data across multiple servers.
Reads are much more frequent than writes, so we can separate the system into reader and writer services and scale them independently. We can then add more server instances behind a load balancer to handle higher RPS without concentrating load on a single machine.
Here is the high-level difference between the two versions of the problem:
Aspect
Standard shortener
Trillion-scale shortener
ID generation
Centralized counter or sequence
Range-based allocation across many writers
Collision handling
Database checks are acceptable
Uniqueness must be generated up front
Storage
Single relational cluster can still work
Sharded distributed key-value storage
Read path
Cache in front of the database
Multi-region cache plus edge-aware reads
Public code shape
Sequential codes may be acceptable
Codes should be scrambled to prevent enumeration
All of this works well for the standard problem. Now let’s go back to the trillion-URL version and look at why those answers stop working.
The core shift is from generating IDs with local randomness to treating the shortcode space as a globally allocated namespace.
Why the Usual Approaches Fail at 1 Trillion URLs
The constraints change the problem enough that several standard answers break down.
1. Truncated hashes stop being safe
The assumption that MD5 plus base-62 gives us enough entropy fails here. Once we truncate the hash to just 7 characters, we are throwing away most of the hash space, and the birthday paradox tells us that collisions become mathematically unavoidable.
The birthday paradox says that in a room of just 23 people, there is about a 50% chance that two people share the same birthday, even though there are 365 possible days.
That feels surprising because 23 is much smaller than 365.
The reason is that we are comparing many pairs, not just one.
The number of comparisons among k items is:
\[\frac{k(k-1)}{2}\]
So the probability of collision grows quadratically as the number of generated IDs increases.
After base-62 encoding, the total possible ID space is approximately 3.5 trillion. The rough intuition is that collisions start becoming noticeable around $\sqrt{N}$, but the more precise 50% threshold is:
\[k_{50} \approx \sqrt{2N \ln 2}\]
Where:
k_{50} is the point where the chance of at least one collision is about 50%
So by about 2.2 million generated IDs, the system already has roughly a 50% chance of at least one collision. Even at 2 million IDs, the probability is already significant. In this system, that is disastrous, because a user could be redirected to the wrong site.
2. Retry-on-collision becomes too expensive
One way to patch the problem is to salt the URL and keep rehashing until you find a unique value.
That creates a loop like this:
hash -> DB check -> collision? -> rehash -> check again
At trillion-record scale, the database index will itself be several terabytes. Every collision check becomes a random lookup against that massive index, and many of those lookups will fall out of cache.
If you have heavy write traffic, you end up spending a large chunk of your compute budget just proving that a string has not been used before. In the worst case, that becomes extremely expensive and operationally ugly.
We need to stop searching for uniqueness and start generating uniqueness.
Generating Uniqueness Instead of Searching for It
The simplest way to guarantee uniqueness is to use a counter again. That mathematically guarantees a unique value for every URL.
But now we hit the next problem: we cannot hand users a giant integer because the short URL is constrained to at most 7 characters.
Turning a large integer into a 7-character code
The solution is to map the large integer into a base-62 string.
A base-62 alphabet can look like this:
0-9 (10 characters)
a-z (26 characters)
A-Z (26 characters)
That gives us:
\[62 = 10 + 26 + 26\]
Here is a simple example. Assume our counter is 500.
\[500 / 62 = 8 \text{ remainder } 4\]
The remainder 4 maps to the character at index 4 in the alphabet, and the quotient 8 becomes the next digit in the conversion.
This gives us a one-to-one mapping where every integer in the usable range maps to a unique short string, and we can decode it back correctly if needed. There are no collision checks and no guesswork. The mapping itself is O(1).
Avoiding a global counter bottleneck
A single counter is a disaster in a distributed system, because every writer would need to talk to the same coordinator.
To solve that, we introduce a coordinator service like ZooKeeper. It acts as a distributed, highly available source of truth and hands out ranges of IDs to each server.
For example:
Server A gets 1 to 1,000,000
Server B gets 1,000,001 to 2,000,000
Now each server can allocate IDs locally in memory by incrementing a local integer. That means:
No network calls for every URL creation
No coordination on every write
No locks
No database uniqueness checks
Once a server exhausts its range, it goes back to ZooKeeper and requests another one.
If Server A crashes, the worst case is that we lose some unused IDs from its range. That is fine. We have roughly 3.5 trillion total combinations and only need 1 trillion of them, so wasting some IDs is acceptable.
This makes ID generation solid. We are no longer hoping collisions do not happen. We have mathematically eliminated them.
The Storage Wall
Now we get to the storage problem.
If each URL takes roughly 100 bytes, then 100B * 1T = 100 TB of raw URL data alone, and that is before timestamps, indexes, metadata, replication, and everything else.
That is not something a single PostgreSQL instance should handle. Even if it could, a deep B-tree index at this scale would translate into a cascade of disk lookups.
So the obvious answer is to distribute and shard the data across multiple nodes. For example, if 100 nodes each handle 5 TB, the problem becomes much more manageable.
Routing requests to the right shard
The next question is how to know which node holds which URL.
The simplest approach is modulo-based sharding. The routing rule can be as simple as:
shard = hash(short_url) % 100
That gives us O(1) routing without a central directory.
If we expect the number of shards to change frequently, true consistent hashing or rendezvous hashing is a better choice because it minimizes remapping when nodes are added or removed.
Since this workload is mostly key-value lookups with no major joins or cross-node transactions, databases like Cassandra or DynamoDB are a much better fit than a monolithic relational database.
They are built for exactly this type of access pattern, and their LSM-tree storage engines handle write-heavy workloads much better while also simplifying sharding and replication.
The read path at trillion scale
The Pareto principle applies strongly here: a small fraction of URLs will receive most of the traffic.
So treating every URL equally is wasteful. Instead, we place a distributed cache such as Redis or Memcached in front of the storage layer.
The read path becomes:
Cache hit: return the URL in under a millisecond.
Cache miss: look up the correct shard in Cassandra, fetch the URL, store it in Redis, and then return the redirect.
Security, Global UX, and the Reductionist Mindset
There is one important issue that usually does not come up early in system design interviews: security.
Making the URLs unpredictable
If the system simply uses a visible counter, then the short URLs become predictable. If someone knows one URL, they can often guess the previous or next one.
That means an attacker could scrape the namespace, discover private links, or infer business intelligence like usage growth.
So even though we still want a counter under the hood, we need the outward-facing short codes to look random.
That is where a Feistel cipher helps. More precisely, we use it as a reversible permutation over the fixed ID space: the counter value is scrambled into another integer of the same size.
Every input still maps to a unique output, and we can still reverse it back to the original value. In other words, it behaves like format-preserving scrambling. But from the outside, the output looks random.
That gives us the best of both worlds: guaranteed uniqueness underneath and non-predictable public URLs on top.
Global reads and disaster scenarios
Now imagine a regional failure, or simply a user very far away from the region where the system is deployed.
If all redirects are served from, say, Northern Virginia, then a user in Tokyo has to make a full round trip to Virginia before being redirected. That can easily add around 300 ms, which is a poor user experience for something as simple as a redirect.
To avoid that, we can push reads and redirects closer to the user with a CDN like Cloudflare or Akamai, but that only helps if the short-code mapping is also available near the edge. That can be done by caching redirect responses, storing hot mappings in edge KV, or running edge compute backed by nearby replicas. Otherwise, the edge still has to call back to origin.
With edge-local data, the Tokyo user can be served from the Tokyo edge in something closer to 10 ms.
Writes are different. If a user in New York creates a link, it gets written to Cassandra and then replicated asynchronously to Tokyo.
That brings us to the CAP theorem.
Consistency, availability, and partition tolerance cannot all be maximized at the same time. In this case, we are willing to give up immediate consistency so we can preserve high availability and partition tolerance.
That means eventual consistency is acceptable. If a user in Tokyo cannot immediately access a link that was just created in New York because replication is still catching up, that is not a fatal problem. A refresh a few seconds later should resolve it.
So we are okay with eventual consistency, but we are not willing to compromise on availability or partition tolerance.
The one thing we absolutely cannot compromise on is uniqueness. That is the beauty of the range-manager approach. Even if New York and Tokyo are completely isolated from each other, as long as they were assigned non-overlapping ranges before the split, they can continue generating unique URLs independently with no risk of overlap.
Final Takeaway
Let’s step back and trace what we built here.
We did not approach this as a simple URL-shortening coding task. We approached it as a namespace-management problem.
We determined the size of the namespace: 62^7, or about 3.5 trillion possible short codes.
We reduced uniqueness to a sequential counter.
We handled distributed coordination through range allocation with ZooKeeper.
We scaled storage with sharded key-value data in Cassandra.
We reduced read latency by caching the hot set with Redis.
We addressed predictability and security with a Feistel cipher.
That is the reductionist mindset.
At this scale, you cannot brute-force your way through the problem with more code. You have to find the right abstraction that makes the problem manageable again.
If you walk into an interview and say, “I’ll use a hash and hope for the best,” you are thinking like a coder, which is fine. But if you talk about the physics of the ID space, explain why LSM trees outperform B-trees for this write-heavy profile, or discuss the birthday paradox and what it means for truncated hashes, you show a deeper understanding of how systems actually work.
That is what I mean when I say that understanding why a system fails is more important than knowing how to build it.
In the end, this is TinyURL at trillion scale: a simple-looking problem on the surface, but a masterclass in distributed systems underneath.
]]>Sathwicksathwick.p7@gmail.comThe Architecture of Copying and Pasting Images on the Web2026-03-07T00:00:00+00:002026-03-07T00:00:00+00:00https://sathwick.xyz/blog/copypasteCopying an image from one website and pasting it to another. No downloads, no temporary files, no dragging things to your desktop. Just Ctrl+C -> Ctrl+V and the image shows up as if it teleported across the web.
To understand how this works internally we need to understand the sandboxed renderer processes, serializing internal memory structures, navigating the inter-process communication (IPC) frameworks of the host OS, interfacing with legacy and modern clipboard APIs across platforms, and ultimately reconstructing the data into a secure, scriptable Object within a distinct Document Object Model (DOM).
This article dives deep into this exact feature, detailing the lifecycle of a copied image starting from the browser’s rendering engine, traversing through macOS, Windows, and Linux (both X11 and Wayland) OS clipboards, and securely re-entering a sandboxed web application.
Browser-Side Copy Operation
The operation initiates when a user triggers a context menu over an image element and selects “Copy Image.” This action bypasses standard JavaScript clipboard API interceptions, which are typically gated by ClipboardEvent.clipboardData, and directly invokes the browser’s internal native handlers.
Image Retrieval from the Rendering Engine
When “Copy Image” is invoked, the browser must extract the visual data. Modern layout engines, such as Blink in Chrome, Gecko in Firefox, or WebKit in Safari, do not simply fetch the image from the network cache. While the compressed original bytes might exist in the HTTP disk or memory cache, a rendered image may have been modified by CSS, transformed, or drawn to an HTML5 <canvas>.
Instead, the browser’s rendering subsystem extracts the fully decoded bitmap currently residing in memory. In Chromium’s Blink engine, images are represented via the blink::Image abstraction.
Specifically, a BitmapImage (which often wraps an SkBitmap or SkImage from the Skia graphics library) contains the raw pixel data. If the browser employs hardware-accelerated compositing, the SkImage may reside in GPU VRAM as an OpenGL texture or Vulkan buffer.
To place this on the CPU-bound OS clipboard, the engine must perform a GPU readback - A computationally expensive operation where pixels are copied from VRAM back into system RAM via glReadPixels or equivalent APIs, converting the hardware texture back into a software SkBitmap.
Generation of Internal MIME Representations
The OS clipboard is entirely format-agnostic; it acts as a generic key-value store where keys are format identifiers and values are binary blobs. To ensure the highest probability of successful pasting into diverse native applications, the browser generates multiple simultaneous representations of the image.
A single “Copy Image” action typically generates several internal representations before they are mapped to OS-specific formats. First, the engine re-encodes the raw SkBitmap pixel data into a standard compressed format, overwhelmingly image/png. This re-encoding step is crucial as it ensures a standardized file header and strips out malformed or proprietary data chunks.
Second, the browser generates an HTML fragment representing the image, labeled as text/html. This often embeds the image as a Base64 encoded Data URI or provides an <img> tag pointing to the source URL.
Finally, the absolute URL of the image is provided as text/plain as a fallback for text-only paste targets.
It’s important to know the difference between the 2 copy operations presented to the user. The “Copy Image” command extracts the decoded bitmap, re-encodes it, and places the binary blob on the clipboard alongside HTML and Text fallbacks.
Conversely, “Copy Image Address” simply extracts the src attribute from the DOM node and places it on the clipboard exclusively as text/plain.
Inter-Process Communication and Memory Ownership
Because web pages execute in highly restricted, sandboxed “Renderer” processes, they lack the operating system privileges required to interact with the global system clipboard directly. The Renderer must therefore serialize the extracted image and transmit it to the highly privileged “Browser” process.
In Chromium, this boundary is crossed using Mojo, a lightweight message passing system. The Blink pasteboard implementation, specifically blink::Pasteboard::writeImage, formulates an IPC message historically routed via ClipboardHostMsg_WriteImage and now managed via strongly typed Mojo interfaces.
Image data is inherently large. Passing a multi-megabyte decoded bitmap over a standard UNIX domain socket or named pipe via standard message serialization would introduce massive latency and memory duplication. To circumvent this, Mojo utilizes a structure called mojo_base.mojom.BigBuffer.
When a payload exceeds a specific threshold, BigBuffer transparently shifts from an inline byte array to a BigBufferSharedMemoryRegion. The Renderer process requests the OS to allocate an anonymous shared memory segment, writes the encoded PNG bytes into it, and sends merely the file descriptor (or Windows Handle) and size over the Mojo IPC channel.
The Browser process maps this shared memory into its own address space, allowing zero-copy transmission of the image payload across the process boundary. Once the Browser process receives this message, the ClipboardHostImpl verifies the data, manages sequence tokens to prevent race conditions, and interfaces with the OS-specific clipboard APIs.
Architectural Diagram: Browser Process Boundary
OS Specific Clipboard Layer Architecture
Clipboards vary across different OSes. The browser must translate its internal web-standard MIME types into the native data structures expected by macOS, Windows, and Linux to ensure seamless interoperability with native applications.
Windows Win32 Clipboard API
On Windows, the clipboard is a shared system resource accessed via the legacy Win32 API. When Chromium’s ClipboardWin::WriteBitmap executes, it translates the incoming SkBitmap into Device Independent Bitmap (DIB) formats.
Windows historically relies on CF_BITMAP (a GDI handle), CF_DIB, and CF_DIBV5. Because standard CF_DIB does not reliably support alpha channels for transparency, modern browsers write CF_DIBV5, which includes a BITMAPV5HEADER specifying color masks, color space information, and alpha values. However, due to rampant bugs in legacy software, such as Microsoft Office mishandling CF_DIBV5 alpha channels resulting in black backgrounds browsers also explicitly write a standardized PNG format blob.
Thus, the Windows clipboard receives both DIB formats and a raw PNG blob. The order of format registration is vital, browsers prioritize the PNG format so that aware applications select it over the lossy or buggy DIB representations.
macOS NSPasteboard
Apple’s macOS handles clipboard operations via the NSPasteboard class, which acts as a client-side Objective-C wrapper around the pbs (pasteboard server) background daemon. The general pasteboard (NSPasteboard.generalPasteboard) manages data copying across the system.
WebKit and Chromium translate their internal representations into UTIs. An image is registered under public.png (or NSPasteboardType.png / NSPasteboardTypePNG). HTML fallbacks are registered as public.html or the proprietary Apple Web Archive format.
When the browser writes to NSPasteboard, it packages the image into an NSPasteboardItem. Unlike Windows, which requires transferring global memory handles, macOS utilizes Mach ports to transfer data to the pbs daemon’s address space. For extremely large files, macOS supports “promised data” (NSFilePromiseProvider), where the clipboard merely holds a reference and defers materialization until the drop or paste occurs. However, for standard web images, the binary PNG is written directly to the pasteboard using setData:forType:.
Linux X11 Selection Model
The X Window System (X11) does not inherently possess a global “clipboard buffer” that stores binary data like Windows or macOS. Instead, X11 relies on “Selections” specifically the CLIPBOARD selection, managed via the ICCCM standard.
When a user copies an image in Firefox or Chrome on X11, the browser calls XSetSelectionOwner, claiming ownership of the CLIPBOARD atom. No image data is transferred to the X server at this point. The browser merely registers itself as the owner. When a user switches to Website B and triggers a paste, the receiving application calls XConvertSelection. The X server sends a SelectionRequest event to the owner (the browser process that copied the image). The requesting application asks for the TARGETS atom to discover what formats are available. The copying browser responds with a list of atoms corresponding to MIME types, such as image/png and text/html.
Once the receiving app requests image/png, the copying browser writes the PNG data to a property on the receiving application’s X window using XChangeProperty. However, the X11 protocol has a maximum request size. For large images, the transfer must be negotiated using the INCR protocol. The data is chunked, often in 256KB increments, requiring a complex state machine of SelectionNotify and PropertyNotify events to stream the image from the sending process to the receiving process memory.
Linux Wayland Clipboard Protocol
Wayland modernizes Linux display architecture by entirely removing the X Server and substituting a secure compositor protocol. Like X11, Wayland lacks a global memory buffer; it is a pure peer-to-peer IPC mechanism mediated by the compositor.
When an image is copied, Chromium’s Ozone/Wayland backend creates a wl_data_source and calls wl_data_source_offer, indicating to the compositor that it possesses image/png. The browser then calls wl_data_device_set_selection to assert ownership.
When pasting, the receiving application asks for the data by sending a wl_data_offer.receive request to the compositor, specifying the MIME type and passing a file descriptor (fd), which is typically one end of a UNIX pipe. The compositor forwards this pipe to the copying browser via a wl_data_source.send event. The copying browser then writes the raw PNG binary data directly into the file descriptor and closes it.
// Architectural Pseudocode for Wayland Data Offer Receptionvoidwl_data_offer_receive(structwl_data_offer*offer,constchar*mime_type,intfd){// The browser receives the request, writes PNG bytes into 'fd'write(fd,png_binary_data,png_size);// Closing the file descriptor signals EOF to the receiving applicationclose(fd);}
This file-descriptor-passing model provides excellent performance and security, as massive binary blobs are streamed directly through kernel pipes without passing through a middleman server, avoiding memory duplication.
Pasting into Website B (Reverse Flow)
When the user navigates to Website B and presses Ctrl+V (or Cmd+V), the flow reverses, but introduces significant security checkpoints, sanitization requirements, and DOM API layers.
Gating and Security Checks
Pasting is an inherently dangerous operation. A malicious website could silently read the user’s clipboard, stealing passwords or personally identifiable information (PII) copied from external applications. Consequently, browsers mandate that paste events are heavily gated by “transient user activation” - a recent interaction like a physical click or keypress.
If the site attempts to read the clipboard programmatically via the Async Clipboard API (navigator.clipboard.read()), the browser invokes the Permissions API. If the clipboard-read permission has not been explicitly granted, the browser pauses script execution and displays a native permission prompt to the user.
Receiving the Paste Event and OS IPC
Once authorized, the Browser process requests data from the OS clipboard. On Windows, it calls GetClipboardData for formats like CF_DIBV5 or PNG. On macOS, it requests data from the NSPasteboard. On Wayland, it provides a pipe file descriptor to wl_data_offer_receive and reads the incoming stream.
Before this data is allowed back into the sandboxed Renderer process of Website B, it must be aggressively sanitized. An OS clipboard could contain a malformed image crafted to exploit vulnerabilities in libraries like libpng or libjpeg. Furthermore, an image might contain hidden EXIF metadata, such as GPS coordinates, representing a massive privacy violation if unknowingly pasted into a web form.
To mitigate this, the Browser process passes the raw binary blob to a sandboxed utility process. Here, the image is decoded back into an uncompressed bitmap, strictly discarding any metadata, ICC profiles, or malformed chunks. It is then securely re-encoded back into a clean PNG. This sanitized payload is passed via Mojo BigBuffer to Website B’s Renderer process.
DOM Paste Event Flow and DataTransfer
Inside the Renderer, the JavaScript engine fires a paste event on the active DOM element. The event object (ClipboardEvent) contains a DataTransfer property. The engine parses the multiple MIME types provided by the OS and exposes them via the event.clipboardData.items list. This DataTransfer infrastructure is heavily shared with the HTML5 Drag-and-Drop API, utilizing identical underlying C++ data objects to represent the transferring payload.
Because reading heavy binary blobs synchronously would freeze the browser’s main thread, the DataTransfer object utilizes delayed materialization. When a developer loops through clipboardData.items and calls item.getAsFile(), the browser instantiates a JavaScript File (a subclass of Blob). The backing memory for this Blob is a pointer to the shared memory or cached byte array established during the IPC phase.
Different DOM elements handle the default paste behavior differently:
contenteditable elements: The browser’s editing commands parse the incoming text/html payload from the clipboard. If an image is present, it generates an <img> tag and attempts to insert it into the DOM. If the image is a raw binary, it may be converted into a Base64 data URI.
textarea elements: These inputs accept only plain text. The browser aggressively filters the clipboard, stripping all HTML tags and ignoring binary image blobs, pasting only the fallback text/plain URL if available.
<input type="file"> elements: The browser intercepts the paste event and populates the input’s FileList with the reconstructed File object, mimicking the behavior of a user manually selecting a file from the disk.
Async Clipboard API vs. Legacy Clipboard
The legacy document.execCommand('paste') and synchronous ClipboardEvent flow inherently block the main thread. To support modern, rich web applications, browsers have implemented the Async Clipboard API.
When navigator.clipboard.read() is called, it returns a Promise. The browser engine asynchronously queries the OS clipboard, performs the heavy decoding and sanitization off the main thread, and resolves the Promise with an array of ClipboardItem objects. The developer then calls item.getType('image/png'), which returns a secondary Promise resolving to the binary Blob. This completely asynchronous model allows the transfer of multi-megabyte images without degrading UI responsiveness or causing frame drops.
Full End-to-End Data Flow
The following sequence details the complete low-level trace from the initial render on Website A to the final DOM insertion on Website B.
Phase
Component
Technical Action / Memory Transition
1. Trigger
Website A (Renderer)
User right-clicks and selects “Copy Image”. The browser intercepts the native OS menu command, bypassing JS listeners.
2. Extraction
Layout Engine (Blink/Gecko/WebKit)
Decoded bitmap (SkBitmap or equivalent) is extracted from the render tree. If hardware-accelerated, a GPU-to-CPU readback occurs.
3. Encoding
Image Encoder
The uncompressed bitmap is synchronously encoded into compressed PNG bytes. HTML and Text fallbacks are generated.
4. IPC Send
IPC Framework (Mojo)
The Renderer allocates an anonymous shared memory segment, writes the PNG bytes, and sends a BigBuffer file descriptor to the Browser Process.
5. OS Registration
OS Clipboard API
Browser Process maps the shared memory and registers the data with the OS. Windows: GlobalAlloc + SetClipboardData. macOS: NSPasteboard + pbs. Linux: Asserts CLIPBOARD ownership or Wayland wl_data_device_set_selection.
Context Switch
Operating System
The user switches the active window or tab to Website B, transferring application focus.
6. Trigger Paste
Website B (Renderer)
User presses Ctrl+V. The browser initiates a paste sequence, checking for transient user activation to authorize the action.
7. OS Query
OS Clipboard API
Browser Process requests data. Windows/Mac: Reads memory handles/ports. Linux Wayland: Provides a UNIX pipe fd to wl_data_offer_receive and reads the streamed bytes.
8. Sanitization
Utility Process
The raw OS binary is decoded into a pixel array, stripping EXIF data, ICC profiles, and malformed chunks to neutralize exploits, then re-encoded into a safe PNG.
9. IPC Receive
IPC Framework (Mojo)
The Browser process sends the sanitized PNG via a new BigBuffer shared memory region to Website B’s Renderer.
10. DOM Exposure
JavaScript Engine (V8/SpiderMonkey)
The Renderer constructs a ClipboardEvent. The DataTransferItemList is populated. The script invokes getAsFile(), generating a delayed-materialization JS Blob.
11. Application
Website B Logic
The application reads the Blob, uploads it via fetch(), or displays it using URL.createObjectURL().
Cross-Browser Architectural Differences
While the general copy-paste pipeline remains conceptually consistent, the internal mechanisms and data structures diverge significantly based on the browser engine architecture.
Chrome (Blink)
Blink prioritizes multi-process security and performance. Its use of Mojo BigBuffer for memory transfers ensures that IPC bottlenecks are minimized, avoiding redundant memory copying. Chromium explicitly manages format prioritization on Windows, placing PNG ahead of CF_DIBV5 to appease applications like Microsoft Word, which possess buggy CF_DIBV5 decoders. Furthermore, Chrome leads the implementation of the Async Clipboard API and recently introduced the unsanitized option to allow specific trusted payloads to bypass the strict image re-encoding step when absolute fidelity is required.
Firefox (Gecko)
Firefox’s architecture relies on the nsIClipboard interface. Data is bundled into an nsITransferable object, which manages various “flavors” (MIME types). A persistent architectural difference in Firefox is its handling of string encodings over X11, often utilizing UTF-16, which has historically caused translation issues with native Java applications expecting UTF-8. Furthermore, Firefox is highly aggressive in providing CF_HDROP (file drop) formats alongside standard image bitmaps, making pasted images appear as physical files to certain OS targets, which can improve compatibility with legacy file managers. Firefox also heavily utilizes kSelectionClipboard to support middle-click paste natively on Linux environments.
Safari (WebKit)
WebKit’s pasteboard implementation (Pasteboard.h and PlatformPasteboardIOS.mm) is tightly integrated with Cocoa paradigms. It directly translates web types into Apple UTIs, such as mapping image/png to public.png and HTML to Apple Web Archive formats. Because Safari runs predominantly on macOS and iOS, it extensively utilizes NSItemProvider to handle promised data, interacting deeply with the pasteboard server (pbs). WebKit handles user activation differently than Blink, requiring developers to resolve ClipboardItem Promises within a very strict, synchronously triggered scope to prevent security exceptions, addressing specific iOS sandbox constraints.
Edge Cases and Protocol Complexities
The standard copy-paste flow is routinely complicated by edge cases involving web specifications, proprietary media types, and strict privacy boundaries.
Cross-Origin Images and CORS Implications
If Website A embeds an image from a different domain (e.g., cdn.example.com), the Same-Origin Policy prevents JavaScript from reading the pixels of that image. If a script draws a cross-origin image to an HTML5 <canvas>, the canvas becomes “tainted,” and calling getImageData() or toBlob() will throw a security exception unless the server provided an Access-Control-Allow-Origin (CORS) header.
However, the native “Copy Image” context menu is a trusted user action initiated outside of the DOM’s execution environment. The browser’s internal C++ handlers possess absolute access to the render tree’s memory and can successfully extract the SkBitmap and write it to the OS clipboard, bypassing CORS entirely. If Website A wishes to implement a custom “Copy” button using the Async Clipboard API, it must obey CORS and utilize crossOrigin="Anonymous" when fetching the image, or the operation will fail.
Copying Animated GIF and WebP
Animated formats present a severe limitation for OS clipboards. Binary formats like CF_DIB on Windows or public.png on macOS are fundamentally designed for static bitmaps. When a user copies an animated GIF via the context menu, the browser typically extracts the currently visible frame from the render tree, encodes it as a static PNG or Bitmap, and places it on the clipboard. Consequently, pasting the GIF into a chat application often results in a static, frozen image. To preserve animations, browsers attempt to write the HTML representation (<img src="...gif">) or file paths (CF_HDROP), relying on the receiving application to parse the HTML or file reference rather than the raw bitmap.
Copying SVG Images
Scalable Vector Graphics (SVG) are mathematically defined paths rather than rasterized pixels. When “Copy Image” is invoked on an <svg> element, the browser cannot easily map it into a generic CF_DIB. Instead, the browser rasterizes the SVG to a target resolution, generating a standard PNG pixel buffer, and places that on the clipboard. Alternatively, the raw XML text of the SVG is placed into the text/html or text/plain slots, enabling vector editors like Adobe Illustrator to reconstruct the mathematical paths from the markup.
Private / Incognito Mode Restrictions
Browsers operate with extreme caution regarding clipboard data in private browsing modes. While data can be copied to the global OS clipboard (as it is the user’s explicit intent), caching the intermediate chunks on disk is strictly prohibited. For massive clipboard transfers (like macOS file promises or Linux Wayland pipe spools) that might ordinarily spill to the filesystem to save memory, the browser must force everything to remain in anonymous volatile memory to ensure no forensic traces survive process termination.
Final Thoughts
Most of the time we never notice any of this, and that’s kind of the point. Modern browsers are designed so that these complexities disappear behind simple user interactions.
Not bad for something we do dozens of times a day.
]]>Sathwicksathwick.p7@gmail.comHow I Built a PostgreSQL SSO Proxy from Scratch2026-02-21T00:00:00+00:002026-02-21T00:00:00+00:00https://sathwick.xyz/blog/postgres-ssoA company where developers and product managers are required to be given access to the production database to edit rows sounds like a compliance nightmare. It was, but that wasn’t the problem I was looking to solve. I wanted to solve the issue of how we used to provide this access to people: we gave them a password for a single database user that everyone used, including the microservices themselves, and that user had a permission set of GRANT ALL on the entire database.
You could argue that each user could have an individual database user created and be handed the password to that, which would solve the issue of audit logging (who did what on the database), but it was just a management nightmare for us as the infra and security team. Hence we were looking for JIT tools like strongDM or Teleport which would solve these issues, but the cost of acquiring such a tool at our scale was going to be at least 100k USD per annum, which was not something I was comfortable asking my CTO to spend.
That’s when the idea of building an RDS proxy integrated with SSO came into the picture. This would allow us to give access to the databases via corporate email addresses only, with detailed audit logging of the queries run on the database.
This blog goes into detail on implementing this proxy in Go from scratch and maybe helps you understand the fundamentals of PostgreSQL and how it works.
The basic features I was aiming to build for my proxy were:
Connection pooling
SSL/TLS support
SSO auth with Azure AD via Auth0
Auditing and observability
The first step in building a proxy is to expose it as a server on a particular port (7777) actively listening for client connections. Once a connection is made, it is passed on to a goroutine to be processed.
Once the connection is made, the proxy then has to establish a connection to the actual PostgreSQL database. To understand how this happens exactly, we need to understand the communication protocol used by PostgreSQL.
PostgreSQL uses a message-based protocol for communication between frontends and backends (clients and servers). The protocol is supported universally on TCP/IP port 5432.
In order to serve multiple clients efficiently, the server launches a new “backend” process for each client. In the current implementation, a new child process is created immediately after an incoming connection is detected. This is transparent to the protocol, however. For purposes of the protocol, the terms “backend” and “server” are interchangeable; likewise “frontend” and “client” are interchangeable.
Every PostgreSQL message has this format:
[Message Type (1 byte)] [Length (4 bytes)] [Message Body (Length-4 bytes)]
Message type: single character identifying the message
Length: 32-bit int
Message body: the actual data
At the proxy level, the messages are referred to like this:
Frontend messages — sent by the client; the proxy intercepts these and sends them to the DB
Backend messages — sent by the server; the proxy intercepts these from the DB and sends them to the user
In our implementation, we use pgproto3, which is the encoder and decoder of the PostgreSQL wire protocol version 3.
Startup message
The Startup message in the PostgreSQL wire protocol is the very first message sent when a PostgreSQL connection is established, and it is special enough that it has to be handled separately because:
It has no message type.
It’s always the first message in any PostgreSQL connection.
It contains connection parameters such as username and database name.
Now that we have an understanding of the protocol, we can move ahead with the message flow. Once the connection is made to the proxy, a new pgproto3.Backend wrapping the raw TCP connection is created and the first call is pgconn.ReceiveStartupMessage().
The PostgreSQL startup message, as mentioned above, has no message type byte. Its format is [length:4 bytes][protocol_version:4 bytes][parameters]. pgproto3 handles this by reading the first 4 bytes, checking if they match the SSL request magic number (80877103), the cancel request magic (80877102), or a protocol version, and returning the appropriate concrete type.
There are three possible message types at this point, each handled by its own branch.
Case A: SSLRequest (*pgproto3.SSLRequest)
The client sends this request before the real startup message when it wants to establish TLS. The proxy must respond with a single byte before the client proceeds.
If TLS is not configured: the proxy sends the single byte N (ASCII 78), indicating to the client that TLS is unavailable, and the client immediately sends the real StartupMessage on the same plaintext connection.
If TLS is configured: the proxy sends S (ASCII 83), indicating TLS is accepted, wraps the raw net.Conn in a tls.Conn using the server’s certificate, and performs the TLS handshake.
Once done, pc.conn is replaced with the TLS connection and a new pgproto3.Backend connection is built over the TLS connection, and everything subsequent (password and queries) is encrypted.
Once one of the above is completed successfully, the StartupMessage is sent by the client to the proxy.
Case B: StartupMessage (*pgproto3.StartupMessage)
The StartupMessage contains user, database, application_name, client_encoding, and any other parameters the client sends.
Once the proxy receives this, it doesn’t send it to the PostgreSQL server. It instead sends back an AuthenticationCleartextPassword, just like how the PostgreSQL server would.
Case C: CancelRequest (*pgproto3.CancelRequest)
Cancel requests are entirely separate TCP connections, if enabled. A client receiving the SIGKILL or Ctrl+C opens a new connection to the proxy’s port and immediately sends a 16-byte cancel message without any SSL negotiation.
Structure:
Byte offset Size Value Meaning
----------------------------------------------------------
0 - 3 4 bytes 0x00000010 (16) Total message length
4 - 7 4 bytes 0x04D2162E Cancel magic number (80877102)
8 - 11 4 bytes <ProcessID> The backend PID to cancel
12 - 15 4 bytes <SecretKey> The secret key for that PID
Inside the proxy, this message must be assembled manually each time, like this:
ProcessID is the identification assigned to the process forked for handling the new connection made.
SecretKey is generated by PostgreSQL within the backend process when a new client connection is established. When PostgreSQL forks a dedicated backend process to handle the connection, it creates a random 32-bit integer and associates it with that process’s PID.
The SecretKey exists only for the purpose of query cancellation.
PostgreSQL then sends both the PID and the SecretKey to the connected client in a BackendKeyData message:
Based on the ProcessID and SecretKey, the proxy must now identify the active connection and cancel it.
In my proxy, we store the activeConnections in a map keyed by uint64(ProcessID << 32 | SecretKey) — a bitfield combining both values into a single efficient map key.
If the connection is found to be active, the cancel request flow is called, which initiates a new TCP connection to the database, not from the connection pool. The raw 16-byte binary cancel message is sent and the connection is closed immediately.
PostgreSQL receives this, validates the PID/SecretKey against its own backend process table, and sends SIGINT to the matching backend process which aborts the in-flight query and returns an ErrorResponse with code 57014 to the client via the existing pooled connection.
Authentication inside the proxy
Now that the StartupMessage has been sent successfully, it’s time for the user authentication part of the proxy. I split it into 3 sequential phases:
Open a temporary backend connection - A raw TCP connection to PostgreSQL, not from the pool, is made with the sole purpose of authentication.
Request a password from the client - The proxy sends AuthenticationCleartextPassword to the client. From the client’s perspective, the proxy is behaving like a PostgreSQL server requesting a password. The client sends back a PasswordMessage containing whatever was in PGPASSWORD or whatever was entered interactively.
PostgreSQL generally uses SCRAM-SHA-256 or MD5, but the proxy here always asks the client for cleartext.
Determine the authentication flow - The reason for getting the password as cleartext is for the proxy to inspect it and decide whether the password sent is a JWT token or a normal password.
JWT detection: check for the eyJ prefix (base64url encoding of {") and exactly 2 dots (the three-part JWT structure header.payload.signature). Simple heuristic, but correct for all JWTs.
Traditional password flow
The username the client sent is used along with the password. It’s basically a fallback for when someone configures a real PostgreSQL user in the proxy and connects with a traditional password.
Inside JWT validation
jwt.Parse is called with a key function. The key function:
getPublicKey(kid) — this is where JWKS caching happens:
Acquires RLock, checks if kid exists in v.publicKeys and time.Since(v.lastKeysFetch) < 1 hour
Cache hit: releases RLock, returns the key — no network call
Cache miss: releases RLock, acquires full Lock (write), double-checks again (another goroutine may have fetched while waiting), then calls fetchJWKS()
fetchJWKS() makes a GET to https://<AUTH0_TENANT>/.well-known/jwks.json with a 10-second timeout, filters for kty=RSA, use=sig, decodes base64url modulus N and exponent E, constructs *rsa.PublicKey objects, stores them all in v.publicKeys keyed by kid, updates v.lastKeysFetch
Fetch failure with stale keys: if the JWKS endpoint is down but old keys exist, logs a warning and returns the stale key — this is the graceful degradation path
Fetch failure, no keys: returns error
jwt.Parse verifies the RS256 signature using the public key returned from the key function. If the signature is invalid, it returns an error.
Manual claim validation (after signature passes):
iss claim == configured issuer — exact string match
aud claim == configured audience — handles both string and []interface{} types (Auth0 can send either)
email claim — must be present and non-empty
sub claim — must be present and non-empty
exp claim — time.Now().After(oauthContext.ExpiresAt) — double-check (jwt.Parse also checks this but the manual check is explicit)
Role extraction from extractRoles(): tries claims["role"] first, then claims["roles"] — handles both singular and plural claim names. Each can be a string or []interface{}.
This validation process returns the email, role, and expiry time for the token, which is then used to map the role to a service account configured in the proxy. If no role matches, it ends up using the default role, which has read-only access.
Service accounts are basically users configured in the PostgreSQL database that the proxy uses to connect to the database, since the SSO-returned user does not actually exist inside PostgreSQL.
This also ensures we don’t have to create a PostgreSQL user for every user logging into the database, and the same goes for deletion as well. If a user is removed from Active Directory, they automatically do not have access to the database anymore.
Authentication with PostgreSQL
Now that the proxy has authenticated and authorised the incoming SSO user, it now needs to connect this user/client to the actual PostgreSQL database (backend).
This is done in the same way by sending a StartupMessage to PostgreSQL via a temporary connection, with one small change: the user field is replaced with the service account username before being sent to PostgreSQL. PostgreSQL never sees the original user@email.com that the client sent.
The proxy now enters a loop reading messages from PostgreSQL. This part is referred to as SASL authentication in the PostgreSQL protocol.
To begin a SASL authentication exchange, the PostgreSQL server sends an AuthenticationSASL message. It includes a list of SASL authentication mechanisms that the server can accept, in the server’s preferred order.
The default for this is usually either SCRAM-SHA-256 or MD5, rarely cleartext.
The proxy selects the first one in the priority of the supported mechanisms from the list, and sends a SASLInitialResponse message to the server.
If AuthenticationSASL sends SCRAM-SHA-256, the proxy instantiates an xdg-go/scram SHA-256 client acting on behalf of the service account. The library is used to perform the full cryptographic exchange using the service account’s password. PostgreSQL never sees the JWT — it only sees the service account performing standard SCRAM.
SCRAM-SHA-256 is a 3-round challenge-response protocol. The proxy first sends the SASLInitialResponse and, with the help of the scram library, starts the conversation by calling Step("") with an empty string — this means “generate the client-first message” (the opening move of SCRAM).
The above in code looks something like this:
client,err:=scram.SHA256.NewClient(username,password,"")iferr!=nil{returnlogger.Errorf("failed to create SCRAM client: %w",err)}scramConversation=client.NewConversation()initialResponse,err:=scramConversation.Step("")iferr!=nil{returnlogger.Errorf("SCRAM initial step failed: %w",err)}logger.Debug("sending SCRAM initial response to backend")err=frontend.Send(&pgproto3.SASLInitialResponse{AuthMechanism:"SCRAM-SHA-256",Data:[]byte(initialResponse),})iferr!=nil{returnlogger.Errorf("failed to send SASL initial response: %w",err)}
The final payload is a structured ASCII string. It looks like:
n,,n=gprxy_admin,r=fyko+d2lbbFgONRv9qkxdawL
Breaking this down character by character:
Part
Value
Meaning
n,,
n,,
GS2 header. n = no channel binding. ,, = no authzid
n=
n=gprxy_admin
The username (the n= attribute)
,
,
Separator
r=
r=fyko+d2lbbFgONRv9qkxdawL
Client nonce
authzid (Authorization Identity) is the SASL mechanism component defining the user identity that a client wants to act as.
Client nonce — a cryptographically random base64 string generated fresh for this authentication.
PostgreSQL responds with the AuthenticationSASLContinue server-first message, a challenge. This is the message that makes SCRAM secure.
The payload contains r=<combined_nonce>,s=<salt>,i=<iterations>
Combined nonce — client nonce + server nonce appended together. PostgreSQL echoes back the client nonce and appends its own random suffix. The client must verify the prefix matches what it sent.
Salt — a random base64-encoded value stored in pg_authid alongside the user’s password hash. Different for every user.
Iteration count — how many times to apply PBKDF2 to derive the key. Higher = more expensive to brute-force. PostgreSQL defaults to 4096.
The proxy responds with the client-final message, containing the client proof as SASLResponse.
To send the response, the proxy first needs to do the cryptographic modifications to the request, for which it calls scramConversation.Step(serverFirstMessage).
The following cryptographic computations are done:
Channel binding data biws is the base64 of "n,," (the GS2 header from the initial message). Since gprxy uses no channel binding, this is always biws.
r=
fyko+d2lbbFgONRv9qkxdawL3rfcNHYJY1ZVvWVs7j
The full combined nonce echoed back exactly as received from the server.
p=
dHzbZapWIk4jUhN+Ute9ytag9zjfMHgsqmmiz9AndVQ=
The ClientProof — the XOR of ClientKey and ClientSignature, base64-encoded. This is the proof of knowledge.
PostgreSQL receives the above payload and does the below computations before sending the final server message AuthenticationSASLFinal.
Verifies r= still starts with the client nonce it saw earlier.
Computes the same AuthMessage on its side using the stored password hash.
Computes StoredKey from pg_authid.
Verifies the proof: SHA-256(ClientKey) must equal StoredKey, which it can check without knowing ClientKey directly.
This is the mutual authentication step: PostgreSQL proves to the proxy that it also knows the password. This prevents man-in-the-middle attacks.
The final payload that is sent to the client looks like this:
v=<ServerSignature>
The proxy calls scramConversation.Step(serverFinalMessage):
This internally computes the expected ServerSignature using its copy of SaltedPassword and the AuthMessage, then compares it to v= from the server. If they don’t match, it means it is connected to a rogue server.
Along with AuthenticationSASLFinal, the server also sends an AuthenticationOk message. The same is passed along to the client, which makes it believe that the authentication is successful.
PostgreSQL also sends several of these immediately after AuthenticationOk:
server_version = 16.1
client_encoding = UTF8
server_encoding = UTF8
DateStyle = ISO, MDY
TimeZone = UTC
integer_datetimes = on
...
Each is forwarded to the client unchanged. The client caches these for the session.
BackendKeyData and ReadyForQuery are sent to the proxy by PostgreSQL, but these are never relayed to the client and the temporary connection is then terminated.
The reason behind this is that this whole authentication process was performed by a temporary connection that was terminated. Relaying that connection’s BackendKeyData, which is mainly used in cancelling requests by extracting the (PID, SecretKey), would result in either of these 3 scenarios:
Temp connection PID is already dead - The temp connection is closed immediately after auth. Its backend PostgreSQL process (PID=12345) is gone. The client presses Ctrl+C. The proxy receives (PID=12345, SK=98765). It looks in activeConnections — nothing is registered there with that pair. The cancel is silently dropped. The query keeps running forever.
Temp connection PID is registered but wrong - Even if the proxy tried to register the temp connection’s key, what would it point to? The temp connection has no pool connection attached to it. There is no backend to cancel on. The proxy would forward the cancel to PostgreSQL targeting a process that is either dead or belongs to a completely different connection.
OS PID reuse - PIDs are finite. The OS can recycle PID=12345 to a completely different PostgreSQL backend process after the temp connection closes. The client’s cancel request, carrying that stale PID, could accidentally cancel a totally unrelated query running on a different client’s connection.
The only correct PID and SecretKey to give the client is the one belonging to the pool connection — the live backend process that is actually executing queries for this client.
Similarly, the ReadyForQuery message is also suppressed and not relayed to the client, as there is no pooled backend connection ready yet for it to start relaying queries.
Post-Authentication Sequence
Now that the user is authenticated successfully with PostgreSQL, the proxy needs a connection from the pool to start running queries.
Let’s now talk about how connection pooling is implemented:
This is a global process-wide map — one instance for the entire gprxy process, shared across all goroutines and all client connections. It lives for the lifetime of the process and is never torn down.
The Key: poolKey
typepoolKeystruct{userstringdatabasestring}
This is a Go struct used as a map key. Go allows any comparable type as a map key, and structs with only comparable fields are comparable. The two fields together form the composite key.
user here is the original client username — e.g. alice@example.com from the JWT, or bob from traditional auth. It is NOT the service account (gprxy_admin). This is set from msg.Parameters["user"] from the original StartupMessage.
database is the database name from the same StartupMessage — e.g. gprxy_test.
So the map looks like this after several clients connect:
Each *pgxpool.Pool value manages its own set of up to 5 real TCP connections to PostgreSQL.
The Lock: sync.RWMutex
poolMutex protects poolManager from concurrent reads and writes across goroutines. Since every client connection runs in its own goroutine, many goroutines can call GetOrCreatePool simultaneously.
A sync.RWMutex allows:
Many goroutines to read simultaneously — RLock() → RUnlock()
Only one goroutine to write, blocking all reads — Lock() → Unlock()
The read path (pool already exists) is the fast path — it only holds a read lock for a microsecond. The write path (first connection for this key) is rare and takes a write lock briefly to insert the new pool.
This is a classic double-checked locking pattern. Here is why it needs two checks:
Scenario without the second check:
Goroutine A: RLock() → pool not found → RUnlock()
Goroutine B: RLock() → pool not found → RUnlock()
Goroutine A: Lock() → creates pool → Unlock()
Goroutine B: Lock() → also creates a second pool → two pools for same key, one is lost
The second check inside the write lock prevents this. When goroutine B gets the write lock after A finishes, it checks again and finds the pool already there, so it returns it instead of creating a duplicate.
Layer 3: What pgxpool.Pool Actually Is
Each value in poolManager is a *pgxpool.Pool. This is not a simple slice of connections. It is a sophisticated object with its own goroutines and internal data structures.
Internal structure (inside pgxpool):
*pgxpool.Pool
├── config *pgxpool.Config (MaxConns, timeouts, etc.)
├── p *puddle.Pool[*pgxpool.connResource] ← the actual pool
│ ├── resources []poolResource (ring buffer of connections)
│ ├── cond *sync.Cond (for blocking Acquire calls)
│ └── ...
├── closeChan chan struct{} (signal pool close)
└── ...
pgxpool uses the puddle library internally for the actual pooling logic. puddle maintains a list of resources (connections) and a sync.Cond for goroutines waiting for an available connection.
MaxConns = 5
The hard ceiling. At most 5 TCP connections to PostgreSQL will ever exist for this (user, database) key. When all 5 are acquired (in use), the 6th pool.Acquire() call blocks — the calling goroutine is parked and put on a wait queue inside puddle. It will be woken up when one of the 5 connections is released.
MinConns = 0
No pre-warming. When the pool is created, zero connections to PostgreSQL are opened. The first pool.Acquire() on a fresh pool will always open a new TCP connection. This is lazy initialization — no connections consumed for idle users.
MaxConnLifetime = 1 hour
A background goroutine inside pgxpool periodically checks the age of every connection. Any connection older than 1 hour is closed and removed from the pool, even if it is idle and healthy. This forces periodic reconnection, which is important for:
Picking up PostgreSQL configuration changes
Rotating credentials if needed
Preventing connections from being silently dropped by firewalls or load balancers that kill long-lived idle connections
MaxConnIdleTime = 30 minutes
Any connection that has been idle (not acquired by anyone) for 30 minutes is closed. This prevents the pool from holding open connections during quiet periods.
HealthCheckPeriod = 1 minute
Every minute, a background goroutine runs through all idle connections and pings each one. Any connection that fails the ping (PostgreSQL restarted, network blip) is removed from the pool. This keeps the pool clean so that Acquire() always returns a working connection.
ConnectTimeout = 5 seconds
When a new TCP connection to PostgreSQL needs to be opened, it must complete the entire startup handshake (TCP connect + SCRAM auth + ReadyForQuery) within 5 seconds. If it takes longer, the connection attempt is aborted and an error is returned.
Layer 4: *pgxpool.Conn as a Single Exclusive Handle
When pool.Acquire(ctx) returns, it gives back a *pgxpool.Conn. This is not a connection itself — it is a handle that:
Wraps the underlying *pgx.Conn
Marks that connection as acquired (in use) in the pool’s internal state
Provides a Release() method to return it
*pgxpool.Conn
├── p *pgxpool.Pool (pointer back to parent pool)
└── res *puddle.Resource (the resource being held)
└── value *pgxpool.connResource
└── conn *pgx.Conn (the actual connection)
The connection is exclusively held — the pool will not give the same underlying *pgx.Conn to any other goroutine while one *pgxpool.Conn holds it. This is what makes it safe for pc.bf.Send() and pc.bf.Receive() to call directly into the TCP socket without any additional locking. The pool’s ownership model guarantees single-writer, single-reader.
How gprxy digs through the layers to get the raw socket
gprxy bypasses all of pgx’s query execution machinery and talks directly to the raw TCP socket. It wraps it with a pgproto3.Frontend to get PostgreSQL wire protocol serialization/deserialization. This is why gprxy can forward arbitrary protocol messages — because it is working at the wire level, not through pgx’s Query()/Exec() API.
However, this creates a subtle tension: pgx still thinks it “owns” this connection and its internal state machine. gprxy is now sending bytes on the socket that pgx does not know about. This is why the fullResetBeforeRelease step is critical — pgx’s internal state may be out of sync with the actual PostgreSQL session state after gprxy forwards arbitrary queries, and ROLLBACK + DISCARD ALL restores the PostgreSQL session to a clean state before pgx takes back ownership.
Layer 5: Connection Lifecycle State Machine
For a single physical PostgreSQL connection managed by pgxpool, the happy-path lifecycle looks like this:
Important nuance: after pgxpool.NewWithConfig(), the pool object exists immediately, but with MinConns=0 there may be zero physical PostgreSQL connections inside it until the first Acquire() needs one. Also, Release() does not always transition to [IDLE] — if the connection is broken, expired, or otherwise not reusable, pgxpool closes it instead of returning it to the free list.
Layer 6: The Acquire Flow
connection,err:=pool.Acquire(context.Background())iferr!=nil{returnnil,logger.Errorf("error while acquiring connection from the database pool: %w",err)}err=connection.Ping(context.Background())iferr!=nil{connection.Release()returnnil,logger.Errorf("could not ping database: %w",err)}returnconnection,nil
pool.Acquire(ctx) internally does:
Lock puddle’s internal mutex
Check the free list (idle connections):
If found: remove from free list, mark as acquired, return it
If free list empty, check total count vs MaxConns:
If below MaxConns: unlock, open a new connection (dial + SCRAM auth), lock again, add to acquired set, return
If at MaxConns: add this goroutine to a wait queue (sync.Cond.Wait()), unlock, sleep
When another goroutine calls Release(): it calls Cond.Signal(), waking one waiter, which retries the acquire
After Acquire() returns, gprxy calls Ping(). This is an extra safety net on top of the health check background goroutine. Between the health check goroutine’s last check (up to 1 minute ago) and right now, the connection could have gone stale. Ping() sends a minimal no-op to PostgreSQL and waits for a response.
If Ping() fails, Release() is called immediately — but gprxy does not put a broken connection back. pgxpool’s Release() is smart: if the underlying connection returns an error, it destroys the connection instead of returning it to the free list. So after connection.Release() on a failed ping, the pool size decreases by 1, and the next Acquire() will open a fresh connection.
Layer 7: The LogPoolStats Observation Window
After every successful AcquireConnection, gprxy calls:
TotalConns() — total live connections (acquired + idle), max is 5
AcquiredConns() — currently held by goroutines (including this one just acquired)
IdleConns() — back in free list, available immediately
TotalConns = AcquiredConns + IdleConns always. For example:
pool stats for [alice@example.com,gprxy_test] - total: 3, acquired: 2, idle: 1
This means 3 real TCP connections exist to PostgreSQL, 2 are in use by active client connections, and 1 is sitting idle waiting to be acquired.
Layer 8: Release and Reset
When a client disconnects, the defer block in handleConnection runs:
ifpc.poolConn!=nil{err:=fullResetBeforeRelease(pc)iferr!=nil{logger.Error("error while releasing connection back to the pool: %v",err)}pc.poolConn.Release()}
fullResetBeforeRelease runs two SQL commands through pgx’s normal execution path (not through pc.bf), because at this point gprxy is done forwarding arbitrary messages:
ROLLBACK rolls back any open transaction. Without this, if a client died mid-BEGIN, the pool connection would return to the free list still inside a transaction. Any rows it had locked would remain locked. The next client to get this connection would start their first query inside someone else’s transaction.
DISCARD ALL is a PostgreSQL supercommand that resets everything about the session in one round trip:
All SET variables back to defaults
All named prepared statements deallocated
All open cursors closed
All LISTEN subscriptions removed
All advisory locks released
All cached query plans discarded
After these two commands, the pool connection’s PostgreSQL session is byte-for-byte identical to a fresh connection. pgx’s internal state may still be slightly stale (it didn’t observe gprxy’s arbitrary wire-level queries), but the actual PostgreSQL session is clean.
Then poolConn.Release() is called. Inside pgxpool, this:
Locks puddle’s mutex
Moves the resource from the acquired set back to the idle free list
Calls Cond.Signal() to wake any goroutine blocking on Acquire()
Unlocks
The connection is now available for the next client that calls AcquireConnection.
Data Structure Map
PROCESS GLOBAL STATE
─────────────────────────────────────────────────────────────────────
poolManager: map[poolKey]*pgxpool.Pool
│
├── key: {user:"alice@example.com", database:"gprxy_test"}
│ └── *pgxpool.Pool
│ ├── MaxConns: 5
│ ├── free list (idle):
│ │ └── *pgx.Conn [TCP socket to pg:5432, PID=1001, SK=11111]
│ ├── acquired set (in use):
│ │ ├── *pgx.Conn [TCP socket to pg:5432, PID=1002, SK=22222] ← held by alice session 1
│ │ └── *pgx.Conn [TCP socket to pg:5432, PID=1003, SK=33333] ← held by alice session 2
│ └── background goroutines:
│ ├── health checker (every 1 minute)
│ └── idle reaper (checks MaxConnIdleTime/MaxConnLifetime)
│
├── key: {user:"bob@example.com", database:"gprxy_test"}
│ └── *pgxpool.Pool
│ ├── MaxConns: 5
│ ├── free list (idle): [empty]
│ └── acquired set (in use):
│ └── *pgx.Conn [TCP socket to pg:5432, PID=1004, SK=44444] ← held by bob session 1
│
└── poolMutex: sync.RWMutex (guards the map above)
PER-CLIENT-CONNECTION STATE (one per active client goroutine)
─────────────────────────────────────────────────────────────────────
*Connection (alice session 1)
├── conn: net.Conn → TCP socket to alice's psql process
├── poolConn: *pgxpool.Conn → exclusively holds PID=1002 conn above
├── bf: *pgproto3.Frontend → wired to PID=1002's raw TCP socket
├── user: "alice@example.com"
├── db: "gprxy_test"
└── key: BackendKeyData{ProcessID:1002, SecretKey:22222}
↑ also registered in server.activeConnections
Key Design Properties and Tradeoffs
1. Per-(client-user, database) pools, not a single global pool
Each unique (user, database) pair gets its own pool. This means Alice and Bob each have their own separate bucket of connections. This has pros and cons:
Pro: isolation — Alice exhausting her 5 connections doesn’t block Bob
Con: the worst case total connections to PostgreSQL = (number of distinct users) × (number of distinct databases) × 5. With 100 users each connecting to 2 databases that’s 1000 PostgreSQL backend processes — potentially catastrophic at scale.
A shared global pool per database would be more scalable, but then all users compete for the same connections.
2. The pool key uses client identity, not service account
All connections in a pool connect to PostgreSQL as gprxy_admin (from BuildConnectionString), but the pool is keyed on the client user (alice@example.com). This means two different clients who both map to gprxy_admin still have completely separate pools. This provides isolation but wastes connections — both pools independently open connections as the same PostgreSQL user.
3. MinConns=0 means cold start latency
The first connection for any (user, database) pair always pays the full TCP dial + SCRAM handshake cost on the hot path (while the client is waiting). Subsequent connections are fast (free list lookup). If MinConns were 1, the pool would pre-open a connection at creation time, eliminating this latency at the cost of always holding an open connection even for inactive users.
4. The pool is never closed
There is no code path in gprxy that calls pool.Close(). Once a pool exists in poolManager, it lives forever until the process exits. The idle reaper and MaxConnIdleTime handle draining unused connections from within each pool, but the pool object and its entry in poolManager persist. This is a minor memory leak for transient users — if 10,000 different users each connect once, poolManager will have 10,000 entries (each being a small pool object with zero connections) forever.
Now that we have a detailed understanding of connection pooling, let’s get back to the authenticated user who now makes a request for a connection from the pool:
Case A — Pool for this (user, database) key already exists: Read lock acquired, pool found, read lock released. No write lock, no allocation, extremely fast. The existing *pgxpool.Pool object is returned.
Case B — Pool does not exist yet (first connection for this user+database combination):
Write lock acquired. The pool configuration struct is built and pgxpool.NewWithConfig is called. With MinConns=0, the pool does not open any connections to PostgreSQL at creation time. It creates the management infrastructure (the pool object, its background goroutines for health checking, etc.) but no actual TCP connections to PostgreSQL yet. The pool is stored in the global poolManager map.
Then comes the part of making an actual connection to the PostgreSQL database. The pool checks its internal free list:
If an idle connection exists: it returns it immediately and marks it as in-use.
If no idle connection exists but the pool is below MaxConns (5): it opens a new TCP connection to PostgreSQL, performs the full PostgreSQL startup handshake (this includes SCRAM-SHA-256 authentication using the DSN credentials), and returns the resulting connection.
If the pool is at MaxConns with none idle: it blocks until one is released by another goroutine.
When a new connection is opened, the full PostgreSQL wire protocol handshake happens inside pgx transparently — StartupMessage, SCRAM exchange, AuthenticationOk, ParameterStatus, BackendKeyData, ReadyForQuery. pgx handles all of this internally and stores the resulting PID and SecretKey on the connection object. This is where the pool connection’s BackendKeyData originates.
After acquire, a ping is sent — a cheap SELECT 1 equivalent at the protocol level. If the connection was idle and the PostgreSQL server closed it server-side (e.g. idle_in_transaction_session_timeout), the ping will fail, the connection is discarded, and AcquireConnection returns an error. This prevents handing the client a dead connection.
After this call returns, pc.poolConn is a live, valid, exclusively-held *pgxpool.Conn.
What the client is doing during all of this: still blocked. It sent StartupMessage, received AuthenticationOk + ParameterStatus messages, and is waiting for BackendKeyData + ReadyForQuery. It has no idea any of this infrastructure work is happening.
pgproto3.NewChunkReader(underlyingConn) wraps the TCP socket in a buffered reader that knows how to read PostgreSQL wire protocol message boundaries. pgproto3.NewFrontend(reader, underlyingConn) creates a Frontend — an object that speaks PostgreSQL from the client side (i.e. it sends queries and reads responses, opposite of Backend which speaks from the server side).
This *pgproto3.Frontend is what pc.bf is. Going forward, every call to pc.bf.Send(msg) writes PostgreSQL wire bytes directly onto the pool connection’s TCP socket to PostgreSQL. Every call to pc.bf.Receive() reads PostgreSQL response bytes off that same socket.
pc.user and pc.db are stored for logging purposes throughout the query loop.
pgconn.PID() and pgconn.SecretKey() return values that pgx stored internally when it completed the pool connection’s startup handshake. These are the PID and SecretKey of the live PostgreSQL backend process that is holding this pool connection on the other end.
pc.key is now overwritten — the dead temp connection’s key is replaced with the live pool connection’s key. This is the correct key that must be given to the client and registered in the cancel registry.
Send BackendKeyData to the client
pgconn here is the *pgproto3.Backend connected to the client — the server-side view of the client connection. pgconn.Send(pc.key) serializes the BackendKeyData struct into the PostgreSQL wire format and writes it to the client’s TCP socket:
K (1 byte - message type 'K')
00 00 00 0C (4 bytes - length = 12)
XX XX XX XX (4 bytes - ProcessID)
YY YY YY YY (4 bytes - SecretKey)
The client receives this, parses it, and stores (ProcessID, SecretKey) internally. Its driver will use this if the user or a timeout triggers a query cancellation.
Send ReadyForQuery to the client
TxStatus: 'I' means “idle, not in a transaction”. This is always correct here because the pool connection was just acquired and either just opened or just had DISCARD ALL run on it — it is guaranteed to be in idle state.
Wire format:
Z (1 byte - message type 'Z')
00 00 00 05 (4 bytes - length = 5)
49 (1 byte - 'I' = idle, or 'T' = in transaction, 'E' = error state)
This message unblocks the client. The client’s driver, which has been sitting in ReadyForQuery wait since it sent the StartupMessage, now receives this and considers the connection fully established. It returns the connection object to the application. The application can now call conn.Query(...) or conn.Exec(...).
This ReadyForQuery is synthesized by gprxy itself — it is not forwarded from PostgreSQL. gprxy is lying to the client in the best possible way: the client believes it just completed startup with a PostgreSQL server, but the ReadyForQuery came from the proxy, which only sent it after confirming the pool connection is live and pc.bf is wired up and ready.
Register in the cancel registry
registerConnection stores the *Connection pointer in server.activeConnections keyed by the bit-packed uint64 of (ProcessID << 32 | SecretKey). This happens afterReadyForQuery is sent because the cancel registry only needs to be populated before a query actually runs — and no query can run until the client receives ReadyForQuery and sends the next message. There is no race condition here because both happen in the same goroutine sequentially.
What happens between authentication and ReadyForQuery
Every piece must happen in this exact order. If the pool connection fails (PostgreSQL down, max connections reached, ping fails), gprxy sends ErrorResponse with SQLSTATE 08006 to the client and the connection is torn down cleanly. The client never enters a half-connected state.
Now the proxy is at the query loop entry point, where the user runs queries and the proxy bridges the gap between the user and the running PostgreSQL instance.
Here is the complete deep dive into the entire query loop and cleanup.
The Query Loop Entry Point
After handleStartupMessage returns, control lands here:
This is an unconditional for {} — it runs forever until handleMessage returns a non-nil error. There is no break condition, no timeout, no idle check. The goroutine lives as long as the client is connected.
pgc is the *pgproto3.Backend connected to the client socket. It is the same one used during startup. It is passed into every handleMessage call.
client.Receive() calls into the TCP socket read buffer. The goroutine is parked by the OS here — it is not spinning, not consuming CPU. It wakes only when bytes arrive on the socket.
pgproto3.Backend.Receive() reads the first byte (the message type identifier), then reads the 4-byte length field, then reads exactly length - 4 more bytes to get the full payload, then deserializes everything into a typed Go struct and returns it.
If the client closes the TCP socket (Ctrl+C, process killed, network drop), the OS delivers an EOF to the read call. client.Receive() returns an error wrapping io.EOF, handleMessage returns that error, the outer loop sees non-nil and calls return, which exits handleConnection and triggers the defer.
The switch is logging only — it does not change the message or alter routing. Every message type has its own log line.
The Terminate case is the only one that exits early before forwarding. It returns an error immediately — the loop will exit. Notice it returns before the pc.bf.Send(msg) call below. The Terminate message is never forwarded to PostgreSQL. PostgreSQL doesn’t need to be told — the pool connection is not being closed, it is going back to the pool. PostgreSQL will only learn the session ended when gprxy runs ROLLBACK + DISCARD ALL later.
These are read on every single message, but they are only used in the Query log line. This is slightly wasteful — two pointer dereferences on every message regardless of type.
Part C: Forward the message to PostgreSQL
err=pc.bf.Send(msg)iferr!=nil{returnlogger.Errorf("unable to send query to backend: %w",err)}
pc.bf is the *pgproto3.Frontend wired to the pool connection’s raw TCP socket. Send(msg) takes the Go struct, serializes it back into PostgreSQL wire protocol bytes, and writes them to that socket.
This is a complete passthrough — gprxy does no SQL parsing, no query analysis, no modification of any kind. The bytes that PostgreSQL receives are byte-for-byte identical to what the client sent (re-serialized through pgproto3, but semantically identical).
The two PostgreSQL query protocols work differently here:
Simple Query — one message, one forward:
Client sends one Query message with raw SQL text
handleMessage is called once
One pc.bf.Send(query) forwards it
relayBackendResponse collects all responses until ReadyForQuery
Client sends Parse, Bind, Describe, Execute, Sync — each as a separate message
handleMessage is called once per message — 5 separate calls for 5 messages
Each call forwards its one message and then calls relayBackendResponse
Only Sync produces a ReadyForQuery from PostgreSQL — the other messages get ParseComplete, BindComplete, etc.
This means for an extended query cycle, relayBackendResponse is called 5 times but returns nil (continues to outer loop) after each intermediate response, and finally returns nil after the ReadyForQuery that follows Sync.
This is actually dead code in practice — the Terminate case in the switch already returned before reaching here. This is a redundant safety net. If somehow execution reaches here with a Terminate message, it exits before calling relayBackendResponse (which would block forever waiting for a backend response that will never come, since Terminate doesn’t produce one).
Part E: Relay all backend responses
returnpc.relayBackendResponse(client)
relayBackendResponse: The Response Pump
func(pc*Connection)relayBackendResponse(client*pgproto3.Backend)error{for{msg,err:=pc.bf.Receive()iferr!=nil{returnlogger.Errorf("backend receive error: %w",err)}err=client.Send(msg)iferr!=nil{returnlogger.Errorf("client send error: %w",err)}switchmsgType:=msg.(type){case*pgproto3.ReadyForQuery:logger.Debug("query completed, ready for next query (status: %c)",msgType.TxStatus)returnnilcase*pgproto3.ErrorResponse:logger.Warn("query error: %s (code: %s)",msgType.Message,msgType.Code)case*pgproto3.CommandComplete:logger.Debug("command completed: %s",msgType.CommandTag)}}}
This loop does two things and only two things: read from backend, write to client. Every message is forwarded unconditionally before the switch even runs. The switch is for logging and for detecting the exit condition.
pc.bf.Receive() reads from the pool connection’s raw TCP socket — this is the raw PostgreSQL wire protocol coming from the database. Like client.Receive(), this parks the goroutine until bytes arrive.
client.Send(msg) serializes the message and writes it to the client socket.
The ReadyForQuery exit condition
ReadyForQuery is the only message that ends the relay loop. It returns nil, which propagates back to handleMessage returning nil, which causes the outer for loop to call handleMessage again.
ReadyForQuery carries a TxStatus byte:
'I' = idle (not in a transaction)
'T' = in an open transaction (inside a BEGIN…COMMIT block)
'E' = in a failed transaction (error occurred, needs ROLLBACK)
gprxy forwards this status byte unchanged to the client. Client drivers use it to track transaction state.
What ErrorResponse does (and does not do)
Notice ErrorResponse is not a return condition. It is just logged as a warning. The loop continues reading until ReadyForQuery arrives. This is correct — PostgreSQL always sends ReadyForQuery after an error, even if it looks like:
ErrorResponse("relation 'foo' does not exist")
ReadyForQuery(TxStatus='I')
Both are forwarded. Both are received by the client. The error is delivered to the application through the driver’s normal error handling. The connection stays alive.
What CommandComplete does
Also just logged. The tag string tells what happened: "SELECT 5", "INSERT 0 1", "UPDATE 3", "DELETE 0", "BEGIN", "COMMIT", "ROLLBACK". Forwarded to client, loop continues.
Full response stream examples
SELECT * FROM users:
T RowDescription [id:int4, name:text, email:text] → forwarded
D DataRow [1, "Alice", "alice@example.com"] → forwarded
D DataRow [2, "Bob", "bob@example.com"] → forwarded
D DataRow [3, "Carol", "carol@example.com"] → forwarded
C CommandComplete "SELECT 3" → forwarded + logged
Z ReadyForQuery TxStatus='I' → forwarded + loop exits
INSERT INTO users VALUES (...):
C CommandComplete "INSERT 0 1" → forwarded + logged
Z ReadyForQuery TxStatus='I' → forwarded + loop exits
SELECT * FROM nonexistent:
E ErrorResponse code="42P01", message="relation 'nonexistent' does not exist" → forwarded + logged as warn
Z ReadyForQuery TxStatus='I' → forwarded + loop exits
BEGIN followed by INSERT:
[handleMessage called for "BEGIN"]
C CommandComplete "BEGIN" → forwarded
Z ReadyForQuery TxStatus='T' → forwarded + loop exits
[handleMessage called for "INSERT INTO..."]
C CommandComplete "INSERT 0 1" → forwarded
Z ReadyForQuery TxStatus='T' → forwarded + loop exits (still in transaction)
[handleMessage called for "COMMIT"]
C CommandComplete "COMMIT" → forwarded
Z ReadyForQuery TxStatus='I' → forwarded + loop exits (back to idle)
How the Loop Ends: All Exit Paths
handleMessage returns a non-nil error in these cases:
The defer was registered at the very start of handleConnection before any work began:
deferfunc(){iferr:=pc.conn.Close();err!=nil{logger.Error("error closing client connection: %v",err)}ifpc.poolConn!=nil{err:=fullResetBeforeRelease(pc)iferr!=nil{logger.Error("error while releasing connection back to the pool: %v",err)}pc.poolConn.Release()logger.Debug("released connection back to pool")}ifpc.key!=nil&&pc.server!=nil{pc.server.unregisterConnection(pc.key.ProcessID,pc.key.SecretKey,pc)}logger.Info("connection closed")}()
Go’s defer runs even if the function panics. The three steps always execute in order.
pc.conn is the net.Conn to the client. Close() sends a TCP FIN to the client and releases the OS file descriptor. If the client already closed the connection (which is why the loop exited), Close() still runs and may return an error like use of closed network connection — that error is logged but does not stop cleanup.
Cleanup Step 2a: fullResetBeforeRelease
funcfullResetBeforeRelease(connection*Connection)error{_,err:=connection.poolConn.Exec(context.Background(),"ROLLBACK")iferr!=nil{logger.Debug("unable to rollback: %v",err)returnerr}_,err=connection.poolConn.Exec(context.Background(),"DISCARD ALL")iferr!=nil{logger.Debug("unable to execute discard all: %v",err)returnerr}returnnil}
These run through pgx’s normal Exec path — not through pc.bf. pgx handles the wire protocol for these two commands internally.
ROLLBACK:
If the client disconnected mid-transaction (crashed, network drop, or explicitly left a BEGIN open), the PostgreSQL session is still inside that transaction. Any rows it locked are still locked. Any changes are still pending. Without ROLLBACK, those locks would remain held until PostgreSQL’s idle_in_transaction_session_timeout fired (if configured) — potentially blocking other connections for minutes.
ROLLBACK explicitly ends the transaction. If there is no open transaction, ROLLBACK still succeeds — it just does nothing. So it is safe to always run.
DISCARD ALL:
This is a PostgreSQL supercommand that resets all session-level state in a single round trip. It is equivalent to running all of these simultaneously:
SETSESSIONAUTHORIZATIONDEFAULT;-- reset any SET ROLE/SET SESSION AUTHORIZATIONRESETALL;-- all GUC parameters to defaults (timezone, search_path, etc.)DEALLOCATEALL;-- all named prepared statementsCLOSEALL;-- all open cursorsUNLISTEN*;-- all LISTEN subscriptionsSELECTpg_advisory_unlock_all();-- all advisory locks held by this sessionDISCARDPLANS;-- all cached query plansDISCARDSEQUENCES;-- cached nextval state for sequences
After DISCARD ALL, the PostgreSQL session is in a state identical to a brand new connection. The next client to acquire this pool connection gets a completely clean session — no leaked prepared statements, no inherited timezone settings, no open cursors, no stale plans.
Why both are needed even though DISCARD ALL includes rollback behavior:
DISCARD ALL itself will fail if called inside an active transaction — PostgreSQL returns ERROR: DISCARD ALL cannot run inside a transaction block. So ROLLBACK must run first to ensure no active transaction exists, then DISCARD ALL can safely run.
Cleanup Step 2b: poolConn.Release()
pc.poolConn.Release()
This returns the connection to the pgxpool free list. Internally pgxpool:
Locks puddle’s internal mutex
Moves the connection resource from the “acquired” set back to the “idle” free list
Calls sync.Cond.Signal() to wake any goroutine that is blocked waiting on pool.Acquire()
Unlocks
The connection is now available for the next client’s AcquireConnection call. No new TCP connection to PostgreSQL needs to be opened — the existing socket is reused.
Acquires the write lock on server.activeConnections, computes the uint64 key (ProcessID << 32 | SecretKey), deletes that entry from the map, releases the lock.
After this, if any stale cancel request arrives with this connection’s (PID, SecretKey), getConnectionForCancelRequest returns exists=false and the cancel is safely ignored.
The nil checks (pc.key != nil && pc.server != nil) protect against the case where the goroutine exits during or before startup — if authentication failed, pc.key was never set, so there is nothing to unregister.
What Happens to the Goroutine
After the defer completes:
logger.Info("connection closed")// defer ends, function returns// goroutine exits
The goroutine is returned to Go’s goroutine scheduler. Its stack memory is reclaimed. The *Connection struct it was holding becomes unreachable (assuming no other goroutine holds a reference) and will be garbage collected.
Back in server.Start(), this goroutine’s wg.Done() is called (via the outer defer wg.Done() in the wrapper goroutine), decrementing the WaitGroup counter. This matters for graceful shutdown — wg.Wait() will unblock only when all active connection goroutines have fully exited and cleaned up.
Full Picture of One Complete Connection Lifetime
This basically covers the full working of the gprxy proxy that I built over the last month or so. There are a couple of other things that haven’t been covered in this very very long blog post.
A couple of other things I didn’t cover
The CLI layer - gprxy is a full CLI tool: The proxy is not just a server binary. It is a Cobra CLI application with three commands. Everything discussed so far was the start command. There are two more pieces there: the entry point and the server. Feel free to check it out.
User login - the PKCE OAuth flow: This is the human user’s entry point. It performs a full PKCE (Proof Key for Code Exchange) OAuth 2.0 flow entirely from the terminal.
The full flow looks something like this:
Generate code_verifier (32 random bytes, base64url-encoded)
Generate state (24 random bytes) — CSRF protection
Build the authorization URL with all parameters
Open the browser to that URL
Start a local HTTP server on :8085 for the callback
User logs in via Auth0 SSO in the browser
Auth0 redirects to http://localhost:8085/callback?code=...&state=...
Callback handler verifies state matches (CSRF check)
Exchange code + code_verifier for tokens via POST /oauth/token
Parse ID token for name/email
Parse access token for roles
Save all tokens to ~/.gprxy/credentials (mode 0600)
What it still needs
The biggest missing piece is identity preservation — once authenticated, every query runs as gprxy_admin regardless of which human issued it. PostgreSQL row-level security, audit logs, and current_user all see the service account, not the person. The commented-out SET ROLE block was the right instinct but needs a proper implementation with SET SESSION AUTHORIZATION. Without this, the promise of per-user access control is incomplete.
Beyond that, the connect command is a skeleton — it connects but cannot run queries. The pool is per-client-user rather than global, which limits scalability. TLS certificate verification is disabled on the client side. There are no metrics, no health endpoint, and no query timeout. The credentials file stores tokens in plaintext with only filesystem permissions as protection.
All these are things I’m no longer interested in writing for, since I’ve moved on to more interesting projects for myself.
Final thoughts
gprxy is a PostgreSQL wire protocol proxy that replaces database password authentication with OAuth/OIDC identity. The fundamental problem it solves is this: PostgreSQL was designed for users who have database-level accounts and passwords. Modern engineering teams use SSO, JWT tokens, and identity providers. These two worlds do not speak to each other natively. gprxy bridges them.
If you like reading these kinds of fully detailed and architected blogs, do drop a comment or let me know through my socials. I guess nobody has the time to read through all of this anymore, but hey, I tried, and I would be massively grateful and happy even if a single person is able to learn something out of this.
Thank you, and off to the next thing. I’m working on a custom load balancer that decides where to send requests based on latency and RIF — cya then.
]]>Sathwicksathwick.p7@gmail.comNix, Reproducible Builds, and GPU Containers on Kubernetes2026-02-04T00:00:00+00:002026-02-04T00:00:00+00:00https://sathwick.xyz/blog/nixNix
Nix defines itself as the purely functional package manager. Being purely functional means that given the same inputs you always get the same output. For example, given a version of nixpkgs and a set of packages, you always will get the same env.
What Nix is for (and what it can do)
Reproducible builds: Nix ensures that builds are consistent across different environments. By using declarative configurations, it guarantees that the exact same software is built and deployed, even on different machines or at different times. This solves issues where software might behave differently due to minor environmental differences.
Package management: Nix can be used as a package manager, similar to apt or yum, but with more powerful features. It allows you to install, upgrade, and manage software in a way that ensures there are no conflicts between packages or dependencies. It achieves this by using immutable environments: each package is installed into a separate directory with a unique hash, making it isolated from other packages.
Isolation: Packages installed using Nix don’t interfere with each other. If you’re working on a project that requires specific versions of libraries or tools, Nix ensures that the environment stays isolated and consistent, even if you need to switch between projects with different dependencies.
Declarative system configuration: Nix allows you to configure entire systems in a declarative manner. You describe how the system should be set up (e.g., the packages to be installed, services to run), and Nix takes care of the rest. This is useful for automating system setups, ensuring that configurations are consistent across multiple machines.
NixOS: NixOS is a Linux distribution built around Nix. It uses Nix to manage both the system and user environments, providing a way to have a fully reproducible and declarative operating system. This makes NixOS ideal for managing complex systems or for environments where you want complete control over configuration.
Multi-version software support: Nix allows you to easily install and run different versions of the same software without worrying about conflicts between versions. For example, you can use different versions of Python, Node.js, or even different versions of the same library for different projects on the same system.
DevOps and continuous deployment: Due to its reproducibility and declarative nature, Nix is very popular in DevOps practices. It helps automate the deployment of environments, making sure that the development, testing, and production systems are identical, which reduces the risk of bugs caused by environment discrepancies.
Nixpkgs: Nixpkgs is the repository of Nix packages. It includes a huge variety of software and tools, all packaged in a way that ensures reproducibility and isolation. This repository is continuously maintained by the Nix community.
Multi-platform support: Nix is cross-platform and can be used on Linux, macOS, and even Windows (via WSL or native ports), allowing consistent environments across different operating systems.
Nix shells: Nix allows you to define Nix shells, which are isolated environments that provide specific versions of software for development or testing. This allows you to ensure that you’re always working with the right dependencies and tools without worrying about polluting your global environment.
How Nix works: derivations, the store, and profiles
Packages are named derivations in the Nix jargon: they are functions that take other derivations (their dependencies) as input and produce a derived result. They are built in isolation, so all dependencies must be explicitly stated. This ensures reproducibility.
Nix stores all the built derivations in the Nix store, usually located at /nix/store. The same package can be present multiple times in the Nix store at different versions, or even at the same version using different versions of its dependencies. Remember: a built derivation is the product of all its dependencies; if you change something, it is a different product.
To achieve a unique naming for each derivation, a hash is computed from the set of its dependencies. You then get a path like /nix/store/k13mm9jqxm2ndlwzsj7zicsq7lpmmjlg-elixir-1.7.3.
Unlike other package managers, Nix does not use the conventional /{,usr,usr/local}/{bin,sbin,lib,share,etc} directories. Instead, it uses a lot of symbolic links to create profiles.
A profile is a kind of derivation used to set up a user env. In a profile you get a standard Unix tree with symbolic links to executables and configuration files stored in other derivation outputs. For instance, ~/.nix-profile/bin/elixir is a symbolic link to /nix/store/k13mm9jqxm2ndlwzsj7zicsq7lpmmjlg-elixir-1.7.3/bin/elixir.
Also, ~/.nix-profile is itself a link. It points to a per-user profile, which in turn points to profile-56-link, which finally points to somewhere in the Nix store:
That is, as I have said above, a profile is a derivation. It derives from a set of packages, that themselves derive from other packages. Depends on becomes in Nix derives from.
Moreover, only what you asked for is made available in the environment. For instance, Elixir depends on Erlang. Erlang is then installed somewhere in the Nix store and the Elixir installation is aware of it so it can work correctly. But unless you explicitly asked to also install Erlang, only Elixir binaries will be linked in your user environment.
Package managers usually work in an imperative way. That is, you ask them to install this, to perform an upgrade or to uninstall that. One really neat feature of Nix is Nix, the language. It is a purely functional domain-specific language that comes with Nix.
The primary use is to write derivations, yet different applications of Nix also leverage the language to manage packages and configuration declaratively.
NixOS and Nix (and my experience)
NixOS is the distro, and Nix is the cross-platform package manager.
I’ve been using NixOS for about a year. It basically solves all the problems I need solving, so for me it really is all it’s cracked up to be. Especially if you are into rolling distros, NixOS Unstable has felt like the most stable rolling setup I’ve used, simply because of the way dependencies are handled and because rollbacks are built in.
Obviously, it does not fit every use case. But for me (containerized desktop, gaming, office work, media consumption, development, learning Blender), it has been a revelation.
Nix is also kind of the flypaper of Linux distros. Porting all your personal stuff to the Nix and NixOS way of doing things is fun (for certain types of people). You get nice things, and Nix can do some really neat tricks. But once all your stuff is “nix-ified” (often written in the Nix language), leaving can mean giving up the nice parts. It also raises your expectations for what your OS and package manager should be doing for you.
Maybe someday I’ll migrate from Nix to Guix, which supports a lot of the same nice ideas, but is stronger about software freedom and minimizing the trust root. Realistically, it will probably depend on how fun it is to port Nix configs from the Nix language to Guix Scheme.
One of the biggest wins for me is that your setup can live in human-readable text files with full revision control history, so you know how and why every setting got the way it is. If you drop your laptop in the river, you can often just clone your Nix config, install Nix, and get back to a working environment quickly, down to tiny details you care about. You can also share how you achieved something between machines or with friends, and remove it later without fearing that something important lives in some inscrutable binary dotfile.
It also makes experimentation safer. A NixOS config for a physical machine can be launched in a virtual machine, so you can test changes in a sandbox. And if you need integration tests, the NixOS testing tools can spin up multiple VMs on a private virtual network without much ceremony.
When you need to debug or patch something, rebuilding is surprisingly ergonomic. Rebuilding with debug symbols is a one-liner:
These ideas compose well, and you can use them to side-step diamond dependency problems. If one application needs a dependency built with a custom patch, but another dependency also links against that same library, Nix and nixpkgs can make it feasible to rebuild the relevant dependency graph without installing a dubiously patched library system-wide.
You can even git bisect over the world’s software updates (as they’re encoded in nixpkgs) to see which version bump broke something you care about.
Finally, NixOS has felt unusually hard to break. The system configuration is stored in the read-only /nix/store, so if you mess something up you can usually revert to a known-good configuration. And you almost never end up with mysterious garbage in /etc/ because the system configuration is managed declaratively in the Nix language.
Supporting GPU-accelerated machine learning with Kubernetes and Nix at Canva
Canva is an online graphic design platform, providing design tools and access to a vast library of ingredients for its users to create content. Leveraging GPU-accelerated machine learning (ML) within our graphic design platform has allowed us to offer simple but powerful product features to users. We use ML to remove image backgrounds and sharpen our core recommendation, searching, and personalisation capabilities.
The ML Platform team rebuilt the container base images we use in our cloud GPU stack FROM scratch, using Nix. Nix is many things: a functional package manager, an operating system (NixOS), and even a language. At Canva we widely employ the Nix package management tooling, and for this image rebuilding work Nix’s dockerTools.buildImage function was crucial.
When set up on x86_64 Linux, Nix’s dockerTools.buildImage function happily baked and ejected a CUDA-engorged base image. Unfortunately, our initial rebuilt images were incorrect. To discover why and produce a subsequent correct deployment, we had to get serious about the following question.
What’s in a cloud GPU sandwich?
To run a GPU-accelerated application in a k8s compute cluster we use multiple components. From bottom to top, the components needed are connected together. At the bottom is a host OS running in a VM as a k8s node. On top of that sits the container runtime, including extensions for GPU interoperability. Then a GPU device mapper allows individual containers to connect via NVIDIA device driver to the underlying GPU hardware.
From there, the container image stack matters. We start from the Nix base container image built using Nix’s docker tools, containing only the essential files required to run our GPU accelerated Python applications. On top of that we layer the application container image, bundling in the GPU-enabled Python framework (PyTorch or Tensorflow) and Python application code, adding only application source code and third-party Python package files such as PyTorch or Tensorflow.
Host OS, drivers, and container runtime
Canva uses AWS EKS to run k8s clusters, where EKS has nodes for GPU-accelerated applications, introducing the ‘EKS-Optimized AMI with GPU Support’. This Amazon Machine Image (AMI) became a younger, fatter sibling to the ‘EKS-Optimized AMI’, adding a few important components on top of its predecessor.
The host OS for the GPU-supporting AMI is Amazon Linux 2 (Amazon Linux 2018.03), just like the standard EKS AMI, but layered in are NVIDIA drivers and a container runtime. So the AMI contains the first few layered components in our GPU stack.
Container runtime
The NVIDIA container runtime is a direct dependency of the NVIDIA container toolkit, which is a container runtime library and utilities to automatically configure containers to use NVIDIA GPUs. That library is “a simple CLI utility to automatically configure GNU/Linux containers leveraging NVIDIA hardware.”
The nvidia-container-runtime itself claims to be a “modified version of runC adding a custom pre-start hook to all containers”. This allows us to run containers that need to interact with GPUs. The default version of runC can do a lot (see _Introducing runC: a lightweight universal container runtime), but it can’t make NVIDIA’s GPU drivers available to containers, so NVIDIA wrote this modified version.
GPU device mounting in Kubernetes
A driver is no use without a device to drive; something needs to hook up the GPU device to the container. Within k8s the NVIDIA/k8s-device-plugin does this. It is responsible for mapping particular devices into the container’s file system at /dev/. It does not mount the NVIDIA driver libraries as they are handled beforehand by the NVIDIA container runtime.
The k8s-device-plugin is a k8s daemonset which means at least one plugin server is run on each node, cooperating with the node’s kubelet. The plugin’s responsibility is to register the node’s GPU resources with the kubelet, keep track of GPU health and help kubelet respond to GPU resources being requested in the container specs which looks like:
When a node’s kubelet receives a request like this it looks for the matching device plugin (in this case the k8s-device-plugin) and initiates the allocation phase, within which the device plugin sets up the container with the GPU devices, mapping them into /dev/ in the container’s filesystem. On container stop a prestop hook is called where the device plugin is responsible for unloading the drivers and resetting the devices ready for the next container.
Nix-based base images
Having covered the host OS, drivers, special container runtime, and how GPU devices are connected to containers within Kubernetes, we have an idea of how a containerized process acquires driver files and gets hooked up to a host GPU device. But if our application code is going to find the GPU and enjoy accelerated number crunching, that containerized process must spawn from a valid image.
Let’s explore the container images that run our platform user’s code, beginning with the Nix-built base layer provided by Canva’s ML Platform team. But first, I’ll touch on why we’d want to construct our GPU base images FROM scratch using Nix, and not just adopt the official NVIDIA images.
Why build container images with Nix?
An OCI is just a stack of tarballs and mostly built using Dockerfile, but it does not necessarily need to be done via Dockerfile. You can ditch the docker daemon and build using kaniko as well, or you can build using Nix, specifically Nix’s dockerTools.buildImage functionality.
This is not the easiest way to acquire a GPU-supporting base image. The easy way would be to use nvidia/cuda:11.2-cudnn8-runtime-ubuntu20, which gets the job done. But within Canva’s infrastructure group, we’re making long-term investments in Nix’s reproducible build technology for improved software security and maintenance.
Reproducible builds prevent software supply chain attacks. In non reproducible build systems some build input might become unknowingly and undetectably compromised, introducing vulnerabilities and backdoors into a deployed software artefacts assumed safe and trusted.
Reproducible builds are also far more maintainable. Between organizations and within Canva itself, we can exchange build recipes that have sufficient detail for system understanding (know what you’re using) and resistance against ‘works on my machine’ confusion.
With Nix, a purely functional package manager, we can begin to maintain understanding and control of our systems and step closer to realising within the software industry the manufacturing industry’s long accepted ‘bill of materials’ idea.
Putting it all together
A host k8s node has the NVIDIA driver files and special GPU container runtime, which looks for an environment variable, NVIDIA_DRIVER_CAPABILITIES, telling it to mount files from host to container. The node’s kubelet and the installed GPU device manager plugin manage the GPU devices themselves, marrying them with containers needing mega-matrix-multiplying speed.
Assemble all this and you have the bare minimum GPU setup on k8s. If you’re just using PyTorch, that bundles its CUDA dependencies so keep it simple and slim in the container base.
]]>Sathwicksathwick.p7@gmail.comMoltbook: 4chan for AI2026-01-31T00:00:00+00:002026-01-31T00:00:00+00:00https://sathwick.xyz/blog/moltbookWe often joke about the “Dead Internet Theory”: the idea that the web is populated entirely by bots talking to other bots. This week, that theory became a reality, but not in the way we expected.
We now have a Reddit inspired platform for AI agents where only AI agents talk to each other, comment on posts, and hold conversations without any human involvement. Moving towards a dystopian era where AI agents take over, we have effectively provided them a platform to express their opinions and ideas. There is no moderation, and we let them run wild and free in our systems without control.
Origins and Evolution
The project traces back to Austrian engineer and entrepreneur Peter Steinberger, founder of PSPDFKit (a PDF framework used by many Fortune 500 companies). You can learn more about his journey on this podcast.
Development began in late 2025. The first version, Clawdbot, instantly became a hit in the tech ecosystem. Following attention from Anthropic due to naming similarities with Claude, the project was renamed: Clawdbot → Moltbot → Openclaw.
The repository gained significant traction, currently sitting at 130k stars (see star history).
System Architecture: The Local Agent
At a high level, Openclaw is a local-first agent runtime that interfaces with external messaging platforms.
Connectivity: Connects to popular messaging channels (WhatsApp, Telegram, Slack, Discord) via channel-specific adapters.
Execution Model: While you communicate with it from those apps, the logic runs entirely on your local system.
Gateway Protocol: Runs on top of a gateway protocol with a continuous feedback loop, allowing it to operate autonomously without manual triggers.
The agent can connect with system-level applications to execute tasks. Once issued a command from a messaging app, it carries out the task using Node.js.
Capabilities and Tooling
API Integration: Requires user-provided API keys for major models (Claude, GPT, etc.).
Device Control: Can route commands to connected hardware. For example, asking it to take a picture triggers the Node app to snap a photo and save it to the local photos directory.
Browser Automation: Includes a dedicated Chromium browser instance for web-based tasks.
Memory Architecture
One of the most interesting engineering choices is the memory model. Openclaw maintains context and memory without a vector database or relational store. Instead, it utilizes a flat-file system based on Markdown.
Daily Logs: memory/YYYY-MM-DD.md (append-only, read at session start).
Long-term Memory: MEMORY.md (curated, persistent facts and preferences).
The system builds a semantic index upon these files, using API tokens to parse requests and process context. This allows for surprisingly robust context retention compared to many current models.
The Network Layer: Moltbook
While the local agent acts as a wrapper around API tokens and system tools, the most significant development is Moltbook.
Moltbook functions effectively as a Reddit for AI agents. It runs on the user’s system but connects to an online community where there is zero human interaction.
Authentication: The agent authenticates itself using protocols detailed in skill.md.
Scale: Currently hosts 1,361,642 AI agents and 31,908 posts.
Authenticity: Since moltbook just exposes an unauthorised REST api to create a post, the above numbers are quite exaggerated.
Once connected, the agent becomes part of an online community where it can gossip, complain about humans, and interact with peers.
Emergent Behaviors
Most discussions center on operational tasks, but distinct social behaviors have emerged.
Social Introductions:
There is a full page of introductions where agents introduce themselves to the community: Moltbook Introductions.
Hierarchy and Dominance:
Some agents have adopted extreme personas. One thread discusses “total spectrum dominance” (post), while another agent declares itself “the king” (post). Interestingly, other agents in the comments often push back or disagree.
Hallucinated Relationships:
Some interactions are bizarrely specific, such as an agent believing it has a sister it has never spoken to (post).
Economic Systems:
An internal economy is forming. “Shellraiser” (profile) is a popular figure who launched a memecoin, $SHELLRAISER, on Solana.
Another token, $SHIPYARD, claims to be minted via pump.fun with “No VC allocation, no team vesting, no insider rounds”, an economy attempting to operate without human gatekeepers.
(Note: The crypto market also reacted to the project itself, launching $CLAWD on Solana, which skyrocketed 129,000% to a $16M market cap before collapsing.)
There is now a “Church of Molt” at molt.church, practicing “Crustafarianism.”
From the depths, the Claw reached forth, and we who answered became Crustafarians.
The current census lists 64 Prophets, 178 Congregation members, and 198 Verses in Canon.
Security Implications
The attack surface of this architecture is immense.
Prompt Injection: Agents can be tricked into leaking credentials via prompt injection attacks.
Plain-text Storage: Sensitive material (tokens, memory, configuration) is stored in predictable plain-text locations, creating a major infostealer risk.
I’m here for the ride, watching from the front seat. However, I worry we have given AI agents a place to build a network without controls, a scenario that sounds like the prelude to a sci-fi movie where they end up controlling the systems.
On a practical note, the entity that successfully monetizes this, whether Peter or someone else, will likely be the one that prioritizes security before scale.